
商品搜索权重设计做为各大电商的商业机密,网上很少有资料涉及这方面的知识;之前因为项目需要,自己整理过一些权重设计资料,这里和大家分享一个简单的权重计算模型,有兴趣的朋友可以自己再根据需求进行优化。
一、权重概念
权重是反应参数指标在整体评价系统中的重要程度,权重越高,表明该指标越重要。
举个列子,一个学校招生考试,共三个科目:语文(100分)、数学(100分)、英语(100分),最终根据语文30%,数学40%,英语30%的比例进行累计得一个总得分,得分高者优先录取。
其中的百分比就是各科的权重,数学占比40%,则说明学校对学生的数学更加重视。
权重的计算方法有很多中,如:加权计算法、加权平均数法、AHP层次法、优序图法等等,今天我们通过最简单的加权计算法来实现一个商品的权重模型,对其它权重算法感兴趣的朋友可以自己搜索学习。
二、加权法
什么是加权法呢?
还是上面的例子,如果有个考生的成绩如下:语文(85)、数学(90)、英语(80),那么他的加权计算过程为:85*30% + 90*40% + 80*30% = 85.5——就是简单的【成绩 * 比例】 再累加的过程。
把上面的科目映射到商品中,则有如下关系:
- 科目 = 商品属性
- 分值 = 属性分值
- 成绩 = 属性得分
- 占比 = 属性的权
这都是什么意思呢?下面我们来一一说明。
1. 确定权重指标【科目=商品属性】
权重指标这个比较好理解,前面我们讲的标题、品类、品牌等等都属于商品属性。
需要注意的是在权重模型中,并不是商品的所有属性都会参与权重计算的,影响用户搜索习惯、以及销量的属性才会参与计算。
如:品牌、价格、总销量、月销量、浏览量、收藏量、商品评分等;对于不同的品类,部分特有属性也会参与计算,如:服饰品类的材质、适应季节等,手机品类的内存大小、存储大小等。
2. 定义指标满分值【分值=属性分值】
指标满分值就好比给科目定义的满分值一样,只有设置了上限,数据才有对比性,我们才能判断出一个具体的分值所代表的好坏程度。
在商品属性中,部分属性在系统设计之初就已经有分值的定义,如评分,通常都设置为10分制或者5颗星的记分方式。
但是在这里依然需要给他们再重新定义一套权重中的满分值,而不能使用原始的10分制或5颗星来计算,因为后面涉及到了自定义权重的高低,需要动态进行调整。
还有一个需要注意的地方,满分值的定义需要根据属性值的多少来作为依据;如平台有500个独立的品牌,那么品牌的满分值就不应该定义为100,而是1000;否则就会出现扎堆现象,某个分值会出现多个品牌的情况,应该尽量避免这种情况发生。
3. 划分指标分值【成绩=属性得分】
对于科目来说,卷面分已经规定好了,具体能考出多少成绩,这个就得看各位同学自己的发挥了。
商品也一样,属性的满分定义好后,某个具体属性能得多少分值就需要根据统计数据和评分标准进行打分。
首先需要定制评分标准,标准的规定有两种方式:
- 人工经验定义:根据后台的销售数据人为的决定分值,搜索比较多的,销售量高的可以得分高点,反之亦然;如手机品类中的品牌,通常比较火热的就是华为、苹果、小米,其次vivo、oppo、三星等等,人为的依次可以为它们设置得分值:华为(500)、苹果(450)、小米(400)、vivo(380)、oppo(350)、三星(320)。
- 有明确数据参考:根据系统反馈的统计数据,通过计算获得分值;如月销量,默认满分定义为1000分,如果月销量超过5000单,则得1000分,未超过的根据比例计算动态获得的分值。
4. 确定指标的权【占比 = 属性权】
与各科的占比一样,权重模型需要为每个参与计算的属性设置相应的权,这里之所以没有叫占比,是因为通常我们理解的占比是以百分制来计算的,所有参与因素占比最终加起来需要等于百分百。
但是商品模型参数属性比较多,采用百分制会试最终的权重值很聚集,搜索效果并不好。
所以通常采用权的设计方法。什么是权呢?
举个实例,如:数字8692 = 8* 1000 + 6*100 + 9*10 + 2*1,其中千分位的权是1000,百分位的权是100,十分位的权是10,个位的权是1。
我们采用类似的方式给参与权重的商品属性定义权,如比较重要的属性:品牌(100000)、价格(100000)、总销量(10000)、月销量(10000);重要的属性:浏览量(1000)、收藏量(1000);一般的属性:库存(10)、材质(10);其中不同的属性是可以定义相同权的。
理解了以上几点,权重模型的基本框架就设计好了,最终权重值通过累加分值乘以权就可以得到。
三、优化
1. 品类影响
在上述的权重模型中,受品类的影响比较严重。
比如小米品牌下有多款不同品类的商品,假如有手机和电视两个品类,大家对他的手机认可度比较高,所以手机品类下品牌的得分和权相对就会设置的比较高一些;而电视是刚进入市场,大家对他的接受度与老牌厂商比就略显逊色,所以电视品类下品牌的得分和权就应该设置的低一些。
再有一个原因就是如果有品类的特殊属性要参与权重,不同品类的特殊属性是不同的。所以在维护权重模型的基本配置时,应该是以品类为单位去维护,这样才能做到个性化的权重设计。
2. 人工干预
上面通过设置好权重配置后,内部都是通过代码逻辑计算获得的权重值。
但是如果平台需要推广新品,由于新品没有销售数据,所以它的排名默认肯定都靠后;这时就需要设计一个维护入口,通过人工单独为商品增加权重数值,将新品排名提到前面已达到推广目的。
3. 外界因素影响
对于部分商品的个别属性,它的权重值会受一些外部因素的影响。
如服饰和鞋类,它们材质属性受季节的影响;如材质分别为棉绒和涤纶的登山鞋,夏天搜索【登山鞋】这个关键字时,涤纶材质的应该被排在前面,棉绒材质的应该被排在后面;冬天搜索【登山鞋】时,棉绒材质的应该在前,涤纶材质的应该在后,这个在做计算时应该是有依赖条件的。
以上就是加权权重模型的设计方案,希望对你有帮助。
这里再多说一下,为了能够保证商品权重的及时性,生产环境下通常每天晚上都会对商品重新做权重值计算。
最后给出一个商品的模拟示例,有需要的同学根据自己的场景优化一下。
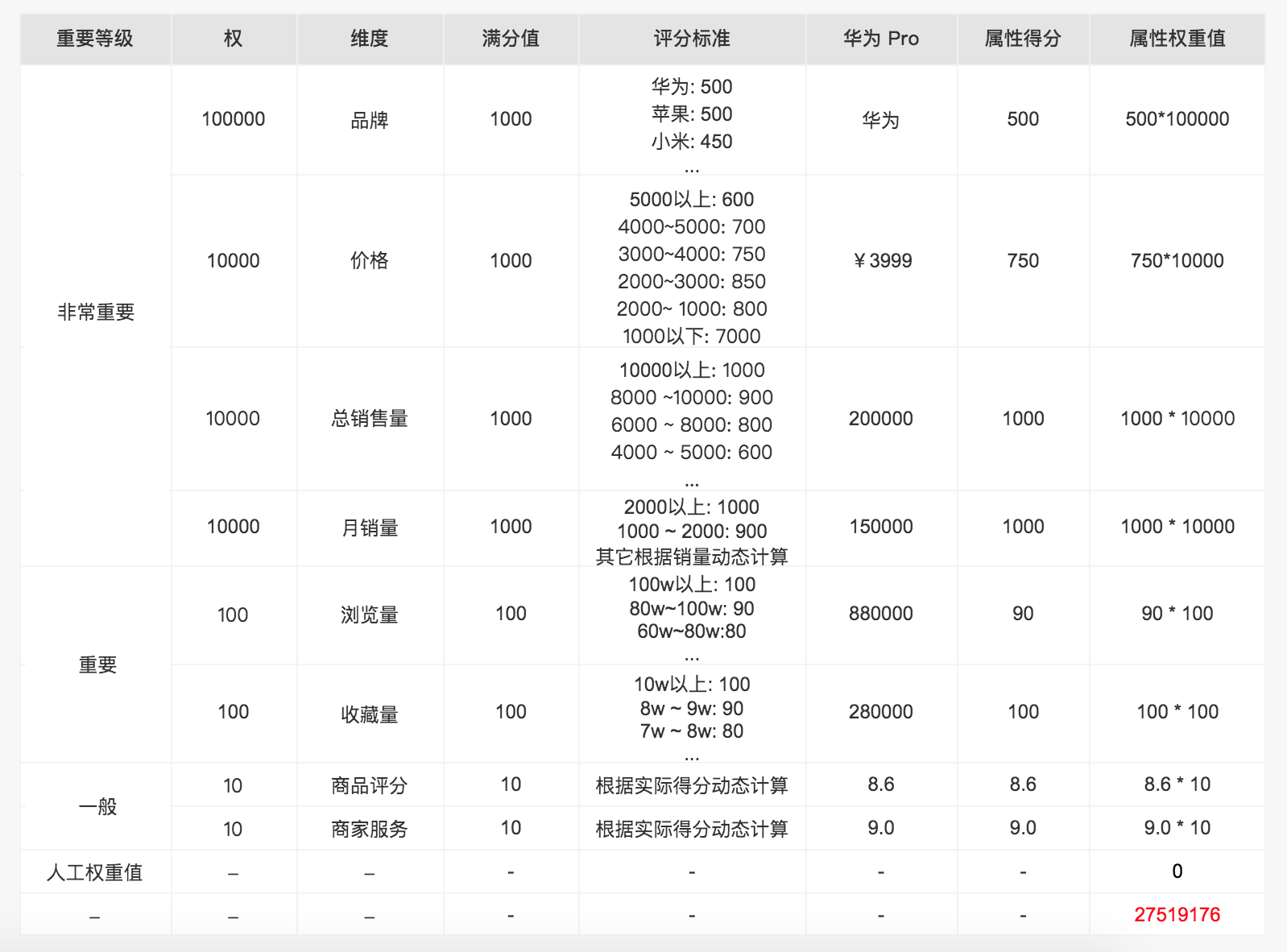
End.
作者:JackLiu
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论