
主流的DNN精排模型基本都是Pointwise的,Pointwise模型优化的是User对单个item的点击可能性,在TopK推荐中,理想的优化方式是优化User对K个Item的整体点击可能性,即Listwise模型。考虑到有推荐需求的应用中可供推荐的Item个数必定不小,再取K进行组合,在对实时性要求很高的推荐场景中实现这样的排序量级基本不现实。要知道当前主流的召回-精排推荐架构中,精排的Item数量一般是几百上千的量级,如果做取N的组合,量级是百千的K次方级别,这太吓人了。虽然工业上实现完全的Listwise推荐模型不现实,但是退而求其次,借鉴Listwise思想,考虑刷次内上下文之间的相互影响,通过引入刷次内的上文信息,进行K次Top1推荐,就可以在Pointwise框架内部分实现Listwise想要达到的效果。引入刷次内上文信息的DNN模型,我们称之为ContextDNN模型。
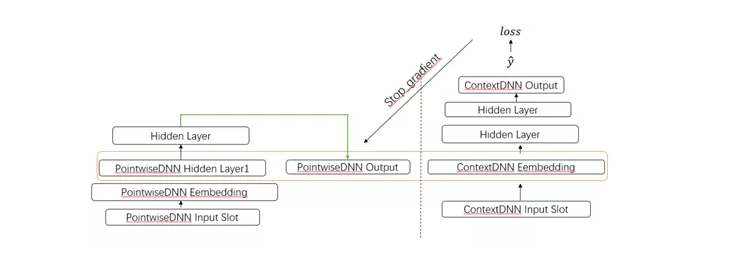
ContextDNN的模型结构如下,左边是常规的Pointwise DNN排序模型,其输出用户对单个Item的点击率预估。Pointwise DNN的输出、Pointwise DNN的第一个隐藏层输出、及刷次内排在该item之前的其它Item信息及交互信息,一起构成ContextDNN的输入。其中,使用Pointwise DNN的第一个隐藏层输出而不是原始的Embedding,是考虑到训练和Serving的性能做的一个折中。注意,在ContextDNN进行梯度传播的时候,Pointwise DNN的输出及其第一个隐藏层输出的梯度不回传过去。
Context Feature部分主要使用了上文已展示的文章标题和内容的类别、关键词、实体词及其次数,以及本文与上文在类别、关键词、实体词等方面的匹配情况这些信息。在线Serving的时候,先按系统正常流程进行排序,此流程融合了Pointwise点击、时长、完播、互动、相似性、多样性、调权、过滤等多重逻辑,这个流程后正常可以将TopK篇文章推出,但如果增加ContextDNN逻辑,则需要针对每个Rank位调用ContextDNN排序服务进行重排。具体为:
在选择Rank为1的文章时,会在已排好序的文章当中选择比如说前100篇文章,调用ContextDNN排序服务,得到该100篇文章新的点击预估分,然后替换原有Pointwise点击预估分进行重排,此时排名第一位的文章作为即将推出的Rank1文章。在选择Rank1的文章时没有ContextFeature,除了Pointwise点击预估分外都是默认值。
然后选择Rank2 的文章,会选择除Rank1文章外已排好序的另100篇文章,调用ContextDNN排序服务,得到该100篇文章新的点击预估分,然后替换原有Pointwise点击预估分进行重排,此时排名第一位的文章作为即将推出的Rank2文章。
后面Rank位的文章的选择与上面流程类似,直至选择好TopK篇文章,该刷文章集合就可以推给用户了。
使用ContextDNN排序的过程,相当于在原有预估的基础上,以串行方式做TopK次预估(有强插逻辑的话会减少),但是ContextDNN的预估文章数量比原有精排文章数量要少一个量级,从千级别到百级别,当然可以根据耗时情况进行调整。整体来说,预估耗时会增加一半左右,由**多毫秒增加到**多毫秒。ContextDNN模型离线gauc收益达到1个百分点,但是初次上线后收益有但是没有达到预期,感觉没有充分发挥出Listwise的能力,还有比较大的优化空间。
做ContextDNN比较有挑战性的地方还是在于工程优化及业务逻辑梳理,主要有以下几点:
一是预估服务需要对PointwiseDNN模型预估分及其隐层输出进行缓存,使得下次请求同文章的ContextDNN预估的时候能够重复利用,不必再次请求Pointwise DNN特征的特征服务及PS服务。
二是相同请求先后从推荐引擎向预估服务调用Pointwise DNN与ContextDNN排序服务的时候必须严格一致,不能因为机器多实验多而导致请求错位。
三是推荐引擎逻辑复杂,特别是各种强插逻辑、打散逻辑、产品逻辑,确保各种逻辑在增加Listwise逻辑后能不相互干扰并正常发挥作用还是比较有挑战性的,只能慢工出细活。
ContextFeature这块还有比较大的优化空间,初期主要是一些当前文章与上文的匹配特征,还可以增加已排序文章的整体性特征,和加入当前文章后的整体性特征,比如加入当前文章后的点击展示时长等统计量等等;在匹配特征里面,与距离近的匹配重要度与距离远的匹配重要度也是不一样的,这个可以考虑一下;同时文章级别的embedding特征可以在模型里面做一些交叉操作。
水平有限,大家有什么想法或者看到这篇文章实践过后有所获,欢迎大家留言讨论,不吝赐教。后期会继续首先通过个人公众号跟大家分享推荐、搜索等方面的实践与思考,感兴趣的朋友也可以添加个人微信好友:Bill_Yae 进行交流。
End.爱数据网专栏作者:billlee专栏名称:推荐系统工业实践专栏简介:介绍工业界最前沿的推荐系统架构、模型及相关实战指南个人公众号:比尔的新世界
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论