
在工业级的推荐系统中,特征一般都是先离散化处理,然后通过深度学习网络学习大规模稀疏特征值(FeatureID)的embedding,从而完成FeatureId到dense embedding的映射。就像一个中国人,我们每个人都会对应一个身份证号,在有关个人的档案信息库里面,输入身份证号,个人的基本信息比如年龄、性别、身高等信息就可以查询得到,我们可以将FeatureID类比身份证号,embedding类比个人的详细信息。
FeatueID从来没有出现过的情形是很常见的,比如新文章、新用户及新行为。如果把所有的FeatureID及与之对应的Embedding看作一个大的词表的话,那么从未出现在词表当中FeatureID本文中称之为未登录FeatureID,对于未登录FeatureID,在训练的时候会首先为其分配一个随机的Embedding,然后通过深度神经网络对Embedding进行更新学习,如果包含该FeatureID的样本足够多,最终学习好的Embedding就能够有效的表征该FeatureID。类似于只要对一个人的信息足够完善,那么这些信息就可以表示这个人了。
但是在Serving的时候呢?对于未登录的FeatureID,也只能为其分配一个随机的embedding或者以固定值代替,这个embedding还不能有效的表征这个特征值,自然基于此做出的预测可能跟真实情况就会有偏差。当然在推荐系统中,特征是很多的,有些特征值缺失,还可以通过其它特征信息来做出相对正确的预测。但是如果平时就对特征值缺失这种状态有所学习,对这种状态有相应的适应,那么自然预测的时候会更为合理。
首先我们来看模型训练和Serving的常见模式,假设模型每一小时训练并更新,那Serving的时候,一小时内模型的Embedding是保持不变的,同时,Serving时候的样本要等到下次训练的时候才能得到学习,也就是说,对于未登录特征值,预估的时候只能为其分配一个随机的embedding,而在实际的应用场景中,这种特征缺失状态是很常见的,并且缺失率可能会很大。如果我们学习的时候,NN参数能够学习和适应这种特征值缺失的情况,那就好了,也就是说NN参数需要在embedding保持不变的状态下学习,这样才能和线上Serving的状态保持一致。
基于这种考虑,可以设计两阶段的训练方式。一个阶段同时训练NN参数及每个FeatureID对应的embedding,这就是常规的模型训练方式,称之为阶段二。另一个阶段基于阶段二训练好的embedding来训练另一套NN参数,称之为阶段一。线下训练的时候先保持embedding不变,只训练用于线上Serving的NN参数,这样就模拟了线上embedding保持不变的情形;然后过渡到另一阶段,同时训练另一套NN参数及embedding,训练完后线上Serving使用这套embedding。但是一开始embedding的学习完全由阶段二完成,等训练指标基本稳定后才开始两阶段的训练模式。
这样处理虽然看起来NN和embedding的训练好像有错位,而且阶段一的线下指标比阶段二的一体化训练模式要差不少,但是线上效果确是使用阶段一的NN,然后使用阶段二的embedding效果更好。因为两阶段训练模拟的就是线上Serving的状态,即Embeding保持不变,而保持线上线下一致的数据状态是机器学习有效的精髓。也可以把这种方式看成迁移学习,阶段二专门训练embedding,阶段一基于已经训练好的embedding来训练NN网络,但是线下训练的时候先训阶段一,因为要让NN网络去学习大量特征值缺失这种状态,然后训练阶段二,去完善embedding的信息。
使用两阶段训练,能够有效的缓解模型的过拟合风险,同时通过先训练NN,再训练embedding,NN网络能够有效的适应特征值缺失的状态,这对于工业级推荐系统来说非常重要。
除了使用两阶段训练方式处理大量存在未登录特征值的情况,还可以新增特征来刻画未登录特征值的具体情况。比如,针对每个特征,如果该特征包含了未登录特征值,则记录下未登录特征值的个数,即针对每个特征增加未登录特征值count特征。如果无未登录特征值,则可以用0来表示,但是因为0与相应的参数W相乘为零,如果0值较多的话,会影响梯度的更新及线上Serving的稳定性,所以可以将count特征统一加1处理。
另外可以尝试将Multi-hot特征(即包含多个特征值的特征,如最近阅读文章关键词)的特征值个数作为特征。在推荐模型之用户行为序列处理一文 中,介绍过对Multi-hot特征常见的处理方式,我们使用Sum-pooling方式来融合Multi-hot特征的特征值embedding效果要好于Average-pooling,可能就是因为未登录特征值的影响,做Average-pooling的时候未将其排除,从而导致Average-pooling后的embedding有偏,把Multi-hot特征的特征值个数加入作为特征,那么可以看成同时利用到Sum-pooling和Average-pooling的优势,当然,如果将multi-hot特征当中未登录特征和其它特征值分开处理,则可以从更细的粒度上去处理embedding。
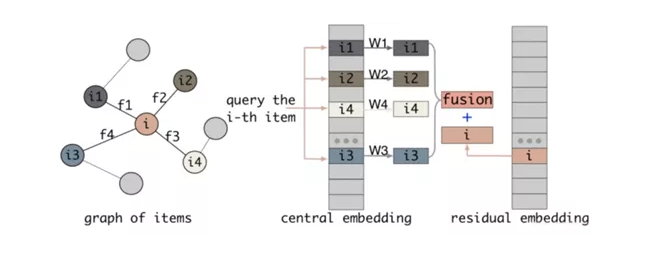
当前DNN模型优化的两条主要路线,即网络结构的优化和embedding特征交叉方式的优化,很多时候两条路线的收益其实都非常地有限,从个人的角度来看,两者并没有深入业务层面做细活,是非常粗糙的优化方式。Google提出的针对不同特征自适应的调整其特征值embedding长度,因为不同的特征其表征空间是不一样的;阿里提出残差embedding的概念,即同一特征不同特征值可以通过离其特征中心embedding的残差embedding来表示,这个其实和FFM的特征域的思想有类似之处。包括本文所分享的embedding处理方式,其实都是从更细粒度的角度来优化embedding,沉得更深,与业务联系更为紧密,这条推荐深度模型优化之路,我觉得前景更为光明,从业务收益角度来讲,毕竟可能前两条路很多人已经走到了死胡同。
讨论一下:
- 可否分享一下实践过的缓解过拟合的好方法?
- 对于embedding的优化,还有什么新路子可否分享一下?论文也可
水平有限,欢迎大家留言讨论或通过公众号加好友交流:
- Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
- Res-embeddingfor Deep Learning Based Click-Through Rate Prediction Modeling
- NeuralInput Search for Large Scale Recommendation Models
End.爱数据网专栏作者:billlee专栏名称:推荐系统工业实践专栏简介:介绍工业界最前沿的推荐系统架构、模型及相关实战指南个人公众号:比尔的新世界
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论