
推荐排序在一个推荐系统当中的重要性毋庸赘言,本文主要结合本人实际工作,跟大家探讨一下构建一个信息流推荐排序系统值得思考的一些问题。
从算法工程师的角度来讲,构建一个信息流推荐排序系统,一般比较关注以下几个问题:
1. 数据从哪里来?
2. 数据如何处理?
3. 用什么模型?
4. 如何训练?
5. 如何线上预估?
上述问题更专业一点的话则是:
1. 如何打标签?
2. 使用哪些特征?
3. 使用什么算法?
4. 如何实现算法,如何训练模型?
5. 怎么使用训练好的模型做预测?
简略的回答是:
1.用户请求日志和用户行为日志拼接得到样本
2.用户特征,文章特征,上下文特征,其它特征
3.策略,机器学习模型,深度学习模型
4.熟悉的编程语言加适当的机器平台
5.根据算法原理定制化开发或者使用开源方案
稍微具体一点:
1.预估排序同时落特征数据,推出后落客户端用户行为,然后根据unique id拼接两者
2.用户、文章、上下文特征这些基础特征,人工特征或者使用算法学习表征
3. LR,GDBT,FM,DNN,它们的组合或者它们的演进
4. 根据原理手撕算法或者使用开源框架,基于单机或者分布式集群训练
5. 根据原理手撕算法然后读取训练好的参数或者使用开源框架直接读取训练好的模型
给一个应用实例:
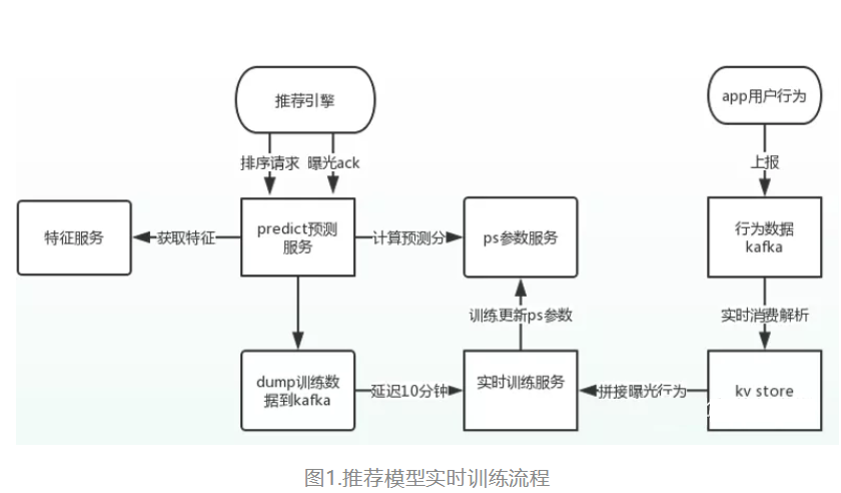
1. 预估同时特征写入kafka:
a. 在线训练数据:缓存后与延时用户点击上报数据流根据唯一request_id进行拼接
b.离线训练数据:kafka特征数据落hdfs,用户行为上报日志落hdfs, 根据request_id或者user_id,doc_id进行离线拼接
2. user,doc,context 特征,部分人工特征(交叉等),离散化:
a. 连续值特征:分桶,hash成int64值
b. 离散单值特征(one-hot):hash成int64值
c. 离散多值特征(multi-hot):将其中每个值hash成int64值, 从特征服务器取值的时候做pooling操作
3. a. FTRL,b. FM,c. embedding+MLP,d. FTRL的w值+MLP:
a. 线性模型,支持大规模特征,调参容易效果稳定,在线更新
b. 自我构造和学习二阶交叉特征,计算复杂度中等,支持召回和排序
c. 工程实现较为复杂,受参数影响较大,模型结构灵活多样,效果不好说
d. 基于既有模型演进,引入非线性,支持模型融合
4. 基于tensorflow的分布式CPU集群:
基于tensorflow的单机多GPU或多GPU集群
5. C++和Go定制化开发预估服务
一个推荐系统当中涉及到的服务众多,基础的有大数据服务,特征服务,参数服务,模型和策略层面有召回服务,排序服务,过滤服务,可谓环环相扣,推荐架构搭建的好坏,直接影响整体推荐的效果。
End.
爱数据网专栏作者:billlee
专栏名称:推荐系统工业实践
专栏简介:介绍工业界最前沿的推荐系统架构、模型及相关实战指南
个人公众号:比尔的新世界
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论