
前言
本篇开始,又会开始一个新的系列,数据结构,数据结构在算法或者是编程中的重要性不言而喻,所以学好数据结构还是很有必要的。本篇主要介绍数据结构的第一个结构——线性表,主要分为以下几部分:
1.概念
2.存储结构
- 顺序存储
- 链式存储
3.存储结构优缺点比较
4.表操作
- 单链表操作
- 双链表操作
注:本系列语言会使用C语言进行,所以要看懂本系列,需要懂一些C语言基础,学python的也别着急,先掌握原理,之后会来一个python实现系列。
概念
线性表是零个或多个具有相同特性的数据元素组成的有限序列,该序列中所含元素的个数叫做线性表的长度,线性表有以下几个特点:
- 首先是一个序列
- 其次是有限的
- 可以是有序的也可以是无序的,你可以把线性表理解成一队学生,可以让这些学生根据身高从小到大排列,也可以随机排成一列
- 线性表的开始元素没有前驱元素只有后继元素,线性表的结束元素没有后继元素只有前驱元素,除了开头元素和结尾元素以外,每个元素都有且只有一个前驱元素和后继元素。
存储结构
线性表的存储结构有顺序存储结构和链式存储结构两种,前者称为顺序表,后者称为链表。
顺序存储结构
顺序表就是把线性表中的所有元素按照某种逻辑顺序,依次存储到从指定位置开始的一块连续的存储空间,重点是连续的存储空间。
数组长度和线性表的长度区别:数组长度是存放线性表的存储空间的长度,存储分配后这个量一般是不变的,线性表的长度是线性表中数据元素的个数,随着线性表插入和删除操作的进行,这个量是变化的。
顺序表的结构体定义:
typedef struct{ int data[maxsize]; //建立存放int类型数据的一个数组 int lengeth; //存放顺序表的长度}
还有比较简洁的写法,如下:
int A[maxsize];int n;
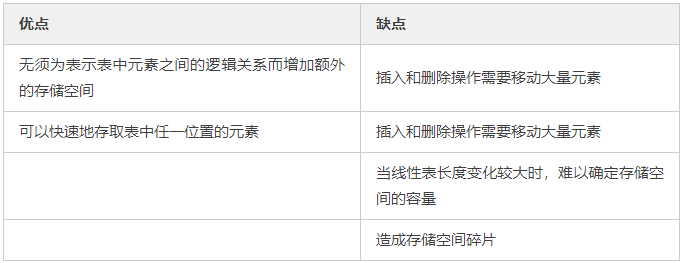
线性表的顺序存储结构的优缺点
链式存储结构
链式存储结构是为了改善顺序存储结构的缺点,顺序存储结构最大的缺点就是插入和删除某一元素时都需要移动大量的元素,这是很耗费时间的。为什么会出现这种移动和删除某一元素时都需要移动大量的元素,是因为相邻两元素的存储位置也是具有相邻关系,他们在内存中的位置也是挨着的,中间没有空虚,不能直接进行插入,要想进行插入,需要先把其他元素进行挪动,同理,若删除某个元素以后,就会流出空隙,也是需要移动其他元素进行补齐。综上所述,造成顺序存储的主要问题是因为相邻两元素的存储位置是相邻的,在内存中的位置也是挨着的。
现在顺序存储问题的原因我们已经知道了,接下来只需要针对性去解决就可以了,让元素之间的位置不必相邻,内存中的位置也不必挨着即可,我们把这种存储结构称为链式存储结构,线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的,这就意味着这些数据元素可以存在内存未被占用的任意位置。还有一点就是在顺序存储结构中,每个数据空间只需要存储数据元素的信息即可,但是在链式结构中,除了要存储数据元素信息外,还需要存储他的后继元素的存储位置。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域,指针域中存储的信息称为指针或链,数据域和指针域组成数据元素的存储映像,称为结点。
1.单链表
n个结点链结成一个链表,即为线性表的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表,单链表是通过每个结点的指针域将线性表的数据元素按其逻辑次序链接在一起。
有的链表是带有头结点的,有的是不包含头结点的,头节点的数据域可以不存储任何信息,可以存储线性表长度等附加信息,头节点的 指针域存储指向第一个结点的指针。当链表是带有头结点的时候,就相当于火车头一样的存在,只是用来表面列车顺序开始的方向,并不乘坐客人。(链表一般都是包含头结点的)
带头结点的单链表中,头指针head指向头结点,头结点的数据域不包含任何信息,从头结点的后继结点开始存储数据信息。头指针始终不等于NULL(指针是指指向下一个元素的的信息,当为NULL时,即不指向任何元素),head->next等于NULL的时候,链表为空。
不带头结点的单链表中的头指针head直接指向开始结点,当head等于NULL(head->=NULL)的时候,链表为空。
链表中整个链表的存取就必须从头指针开始进行,之后的每个结点就是上一个结点的后继指针指向的位置,最后一个结点(终端结点)的指针为空,通常用NULL或^表示。

单链表结点定义
typedef struct LNode{ int data; //data中存放结点数据域 struct LNode *next; //指向后继结点的指针}LNode; //定义单链表结点类型
2.静态链表
前面的单链表是用的指针,但是有的编程语言是没有指针这个功能的,那怎么?聪明的人总是有,有人想出了用数组来代替指针,来描述单链表,让每个数组的元素都由两个数据域组成,数组的每个下标都对应两个数据域,一个用来存放数据元素,一个用来存放next指针。我们把这种用数组描述的链表叫做静态链表。
3.循环链表
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表。
4.双向链表
在单链表的基础上,再在每个结点中设置一个指向其前驱结点的指针域,这样一个结点既可以指向它的前面又可以指向它的下一个,我们把这种链表称为双向链表。
双链表结点定义
typedef struct DLLNode{ int data; //data中存放结点数据域(默认是int类型,也可以是其他) struct DLNode *prior; //指向前驱结点的指针 struct DLNode *next; //指向后继结点的指针}DLNode; //定义双链表结点类型
结点是内存中一片由用户分配的存储空间,只有一个地址用来表示它的存在,没有显式的名称,因此我们会在分配链表结点空间的时候,同时定义一个指针,来存储这片空间的地址(这个过程通俗的讲叫指针指向结点),并且常用这个指针的名称来作为结点的名称,比如下面这个:
LNode *A = (LNode*)malloc(sizeof(LNode)); //用户分配(sizeof)了一片LNode空间,这时定义指针A来指向这个结点,同时我们也把A当作这个结点的名字。
顺序存储和链式存储比较
因为顺序表的存储地址是连续的,所以只需要知道第一个元素的位置,就可以通过起始位置的偏移去获取顺序表中的任何元素,我们把这种特征称为随机访问特性。
顺序表中的数据元素是存放在一段地址连续的空间中,且这个存储空间(即存放位置)的分配必须预先进行,一旦分配好了,在对其进行操作的过程中是不会更改的。
顺序表在插入删除一个元素的时候需要移动大量元素。
因为链表的存储结构是一个元素中包含下一个数据元素的位置信息,下一个包含下下一个,也就是每个数据元素之间都是单线联系的,你要想知道最后一个元素在哪里,你必须从头走到尾才可以,所以链表是不支持随机访问的。
链表中的每一个结点需要划分出一部分空间来存储指向下一个结点的指针,所以链表中结点的存储空间利用率比顺序表要低。
链表支持存储空间动态分配。
链表在插入和删除一个元素时,不需要移动大量元素,只需要更改插入位置的指针指向就可以。
表的操作
表的操作其实主要分为几种:查找、插入、删除
顺序表操作:
1.按元素值的查找算法,
int findElem (Sqlist L,int e){ int i; for (i=0,i<L.length,++i) //遍历L长度中的每个位置 if(e == L.data[i]) //获取每个位置对应的值和e值进行判断,这里的等于可以是大于、小于 return i; //如果找到与e值相等的值,则返回该值对应的位置 return -1; //如果找不到,则返回-1}
2.插入数据元素算法
在顺序表L的第p个(0<p<length)个位置上插入新的元素e,如果p的输入不正确,则返回0,代表插入失败;如果p的输入正确,则将顺序表第p个元素及以后元素右移一个位置,腾出一个空位置插入新元素,顺序表长度增加1,插入操作成功,返回1。
int insertElem(Sqlist &L,int p,int e) //L是顺序表的长度,要发生变化,所以用引用型{ int i if (p<0 || p>L.length || L.length==maxsize) //如果插入e的位置p小于0,或者是大于L的长度,或者是L的长度已经等于了顺序表最大存储空间 return 0; for (i=L.length-1;i>=p;--i) //从L中的最后一个元素开始遍历L中位置大于p的每个位置 L.data[i+1]=L.data[i]; //依次将第i个位置的值赋值给i+1 L.data=e; //将p位置插入e ++(L.length); //L的长度加1 return 1; //插入成功,返回1}
3.删除数据元素算法
将顺序表的第p个位置的元素e进行删除,如果p的输入不正确,则返回0,代表删除失败;如果p的输入正确,则将顺序表中位置p后面的元素依次往前传递,把位置p的元素覆盖掉即可。
int deleteElem (Sqlist &L,int p,int &e) //需要改变的变量用引用型{ int i; if(p<0 || p>L.length-1) //对位置p进行判断,如果位置不对,则返回0,表示删除失败 return 0; e=L.data; //将要删除的值赋值给e for(i=p;i<L.length-1;++i) //从位置p开始,将其后边的元素逐个向前覆盖 L.data[i]=L.data[i+1]; --(L.length) //将表的长度减1 return 1; //删除成功,返回1}
单链表操作
1.单链表的归并操作
A和B是两个单链表,其中元素递增有序,设计一个算法,将A和B归并成一个按元素值非递减有序的链表C,C由A、B组成。
分析:已知A、B中的元素递增有序,要使归并后的C中的元素依然有序,可以从A、B中挑出最小的元素插入C的尾部,这样当A、B中所有元素都插入C中时,C一定是递增有序的。
void merge(LNode *A,LNode *B,LNode *&C) { LNode *p = A->next; //用指针p来追踪链表A的后继指针 LNode *p = B->next; //用指针p来追踪链表B的后继指针 Lnode *r; //r始终指向C的终端结点 C = A; //用A的头结点来做C的头结点 C-> = NULL; // free(B); r = C; while(p!=NULL&&q!=NULL) //当p和q都不为空时,选取p与q中所指结点中较小的值插入C的尾部 { if(p->data<=q->data) //如果p结点的值小于等于q结点的值,则将p的结点指向r,即C,p的下一个结点继续指向p { r->next = p;p = p->next; r=r->next; } else { r->next=q;q=q-next; r=r->next; } } r->next = NULL; if(p!=NULL)r->next=p; if(q!=NULL)r->next=q; }
2.单链表的尾插法
已知有n个元素存储在数组a中,用尾插法(即从尾部插入)建立链表C
void createlistR(LNode *&C,int a[],int n) //需要不断变化的值用引用型{ LNode *s,*r; //s用来指向新申请的结点,r始终指向C的终端结点 int i; C = (LNode * )malloc(sizeof(LNode)); //申请一个头结点空间 C -> next = NULL //初始化一个空链表 r = C; //r为指针,指向头结点C,此时的头结点也是终端结点 for(i=0;i<n;++i): { s = (LNode*)malloc(sizeof(LNode)); //新申请一个结点,指针s指向这个结点 s -> data = a[i] //将数组元素a[i]赋值给指针s指向结点的值域 //此时,结点值域和指针都有了,一个完整的结点就建好了,要想把这个结点插进链表C中 //只需要将头结点指针指向这个结点就行 r -> next = s; //头结点指针指向结点s r = r -> next; //更新r指针目前的指向 } r -> next = NULL; //直到终端结点为NULL,表示插入成功}
3.单链表的头插法
头插法和尾插法是相对应的一种方法,头插法是从链表的头部开始插入,保持终端结点不变;尾插法是从链表的尾部开始插入,保持头结点不变。
void createlistF(LNode *&C,int a[],int n) //需要不断变化的值用引用型{ LNode *s; int i; C = (LNode * )malloc(sizeof(LNode)); //申请C的结点空间 C -> next = NULL //该节点指向为空 for(i=0;i<n;++i): { s = (LNode*)malloc(sizeof(LNode)); //新申请一个结点,指针s指向这个结点 s -> data = a[i] //将数组元素a[i]赋值给指针s指向结点的值域 //此时,结点值域和指针都有了,一个完整的结点就建好了,要想把这个结点插进链表C中 //只需要让这个结点的指针指向链表C的开始结点即可 s -> next = C -> next; //结点s指向C指针的开始结点 C -> next = s; //更新r指针目前的指向 }}
双链表操作
1.采用尾插法建立双链表
void createFlistR(DLNode *&L,int a[],int n){ DLNode *s,*r; int i; L = (DLNode*)malloc(sizeof(DLNode)); //新建一个结点L L -> prior = NULL; L -> next = NULL; r = L; //r指针指向结点L的终端结点,开始头结点也是尾结点 for(i=0;i<n;++i) { s = (DLNode*)malloc(sizeof(DLNode)); //创建一个新节点s s -> data = a[i] //结点s的值域为a[i] r -> next = s; //r指针的后继指针指向s结点 s ->prior = r; //s的前结点指向r r = s; //更新指针r的指向 } r -> next = NULL; //直到r指针指向为NULL}
2.查找结点的算法
在双链表中查找值为x的结点,如果找到,则返回该结点的指针,否则返回NULL值。
DLNode* findNode(DLNode *C,int x){ DLNode *p = C -> next; while(p != NULL) { if(p -> data == x) break; p = p -> next; } return p;}
3.插入结点的算法
在双链表中p所指的结点之后插入一个结点s,核心思想就是将p的指向赋值给s,即让s指向p所指,s的前结点就是p,p的后结点就是s,具体代码如下:
s -> next = p -> next;s -> prior = p;p -> next = s;s -> next -> prior = s;
4.删除结点的算法
要删除双链表中p结点的后继结点,核心思想就是先将p的后继结点给到q,然后让p指向q的后继结点,q的后继结点的前结点就是p,然后把q释放掉,具体代码如下:
q = p -> next;p -> = q -> next;q -> next -> prior = p;free(q);
End.爱数据网专栏作者:张俊红作者介绍:一个数据科学路上的学习者、实践者、传播者个人公众号:俊红的数据分析之路
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论