
1.Spark介绍
Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。那到底是什么,可能还不是太理解,通俗讲就是可以分布式处理大量极数据的,将大量集数据先拆分,分别进行计算,然后再将计算后的结果进行合并。
这一篇主要给大家分享如何在Windows上安装Spark。
2.Spark下载
我们要安装Spark,首先需要到Saprk官网去下载对应的安装包,Spark官网:http://spark.apache.org/downloads.html
第一步点击我红框框住的蓝色链接部分即可。
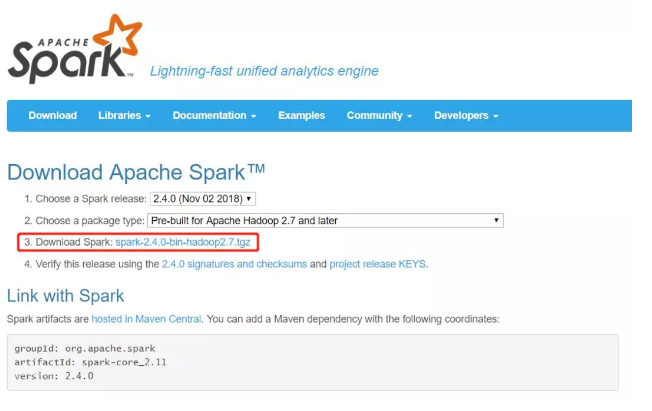
操作了第一步以后会跳转到另一个页面,如下图所示,选择红框框住的部分进行下载,然后选择文件保存的路径进行保存即可。

我们需要把下图中的bin文件所在的路径设置到环境变量里面。
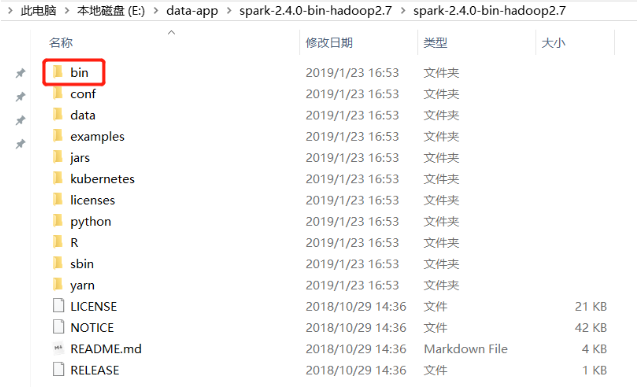
3.Spark环境变量设置
第一步右键我的电脑,然后选择属性,就来到了下图这个界面。
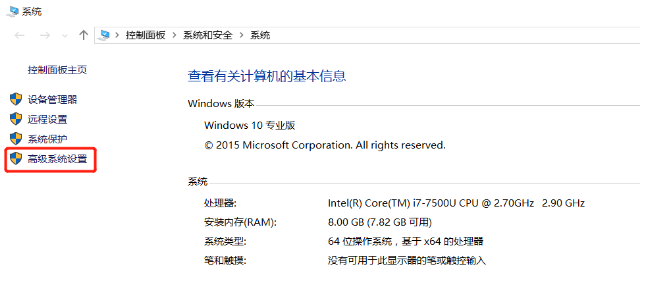
选择红框框住的高级系统系统设置,然后再点击环境变量。
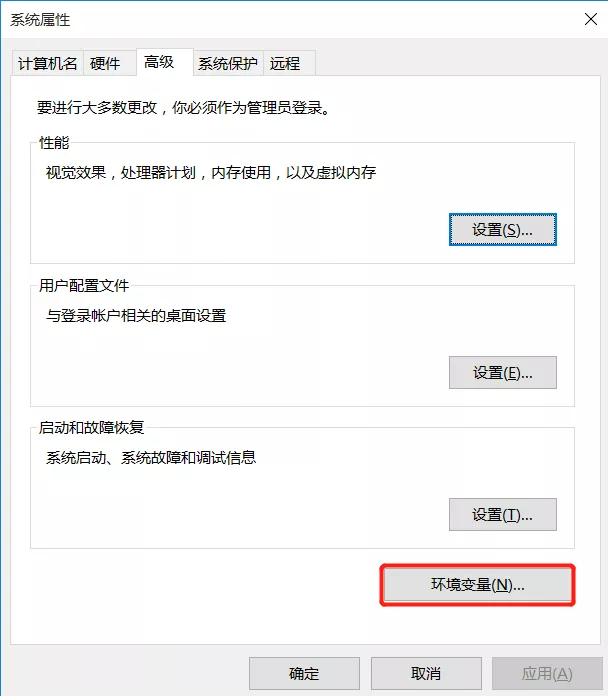
这里我们看到有两个path,一个是用户的环境变量,一个是系统的环境变量,这两个有啥区别呢?
系统的环境变量设置以后对所有登陆这个系统的所有用户都起作用,而用户环境变量只对这个用户起作用,我们一般设置系统环境变量,即系统用户变量里面的path。
先点击path部分把path行选中,然后再点击编辑。
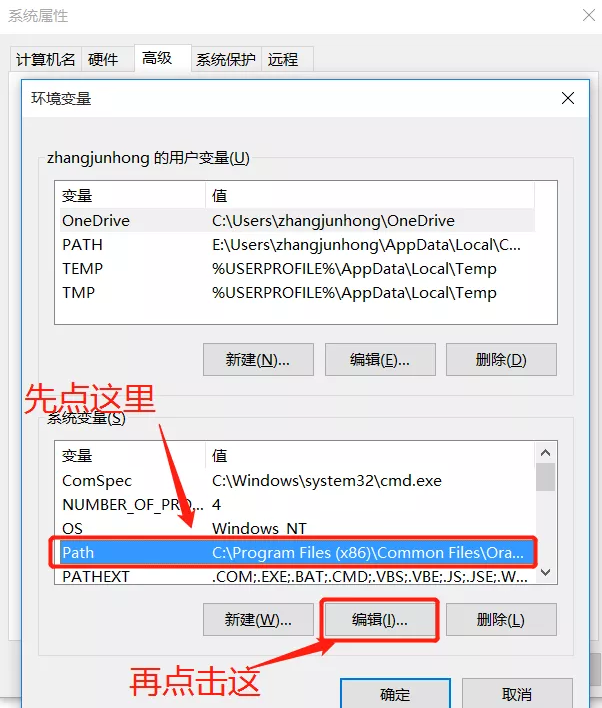
把bin (包含bin) 文件夹所在的路径添加到已有环境变量的后面,并用;隔开,然后点击确定,这样环境变量就配置成功。
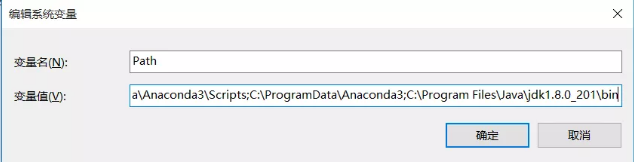
利用组合键Win+R调出cmd界面,输入spark-shell,得到如下界面:
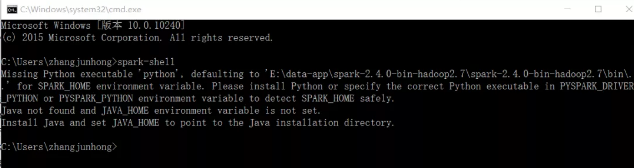
报错Missing Python executable Python是因为没有把Python添加到环境变量中,所以需要先把Python添加到环境变量中,添加方式和Spark添加方式是一样的,只需要找到你电脑中Python所在路径即可。
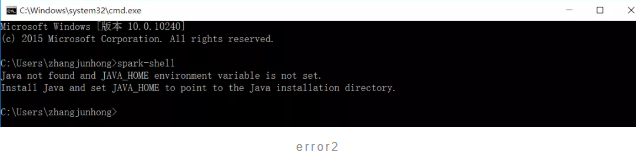
把Python添加到环境变量以后,再次输入spark-shell,没有Python的报错了,但是还有Java not found的报错,所以我们需要在电脑上安装Java。
4.Java下载安装
首先需要来到Java官网去下载对应的Java版本,Java官网:https://www.oracle.com/technetwork/java/javase/downloads/index.html
选择我红框框住的JDK DOWNLOAD,然后就会跳转到另一个页面。
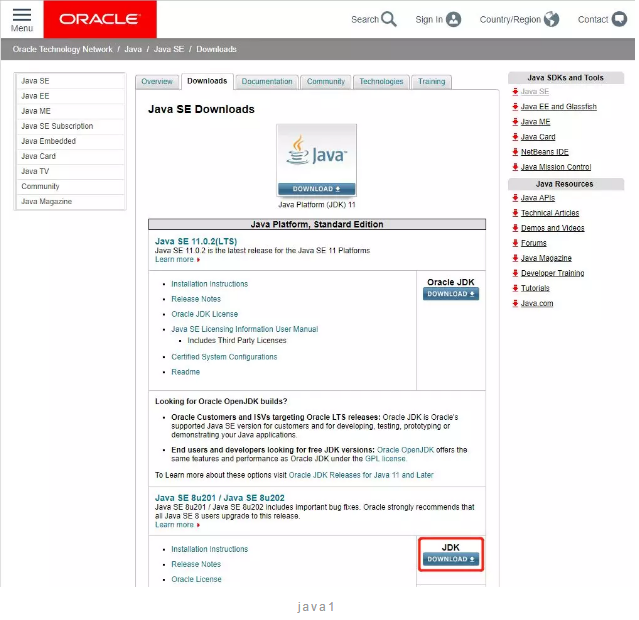
先点击小红框框住的Accept License Agreement,然后再点击下方对应的版本,这里我电脑是Windows 64bit,所以选择Windows x64即可。
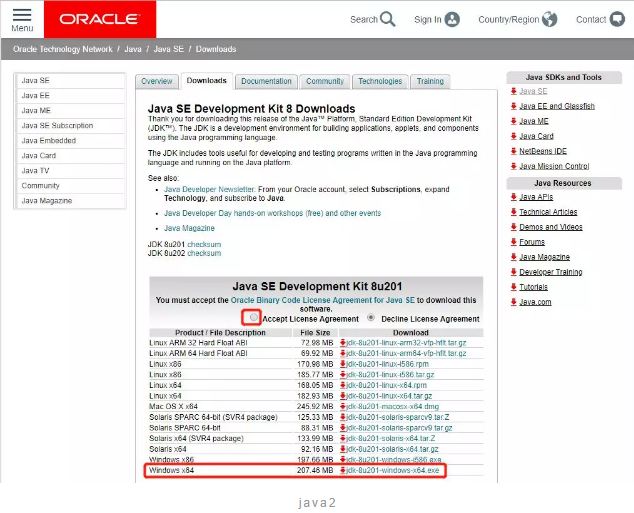
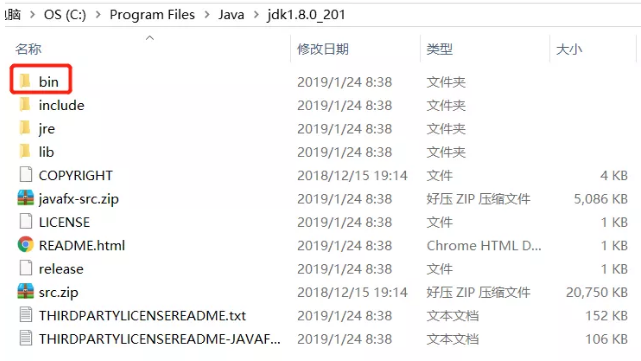
下载好以后是一个.exe文件,直接双击运行即可,等程序安装完成以后,同样需要把安装目录下的bin文件夹添加到环境变量,添加方式与spark添加方式一样。
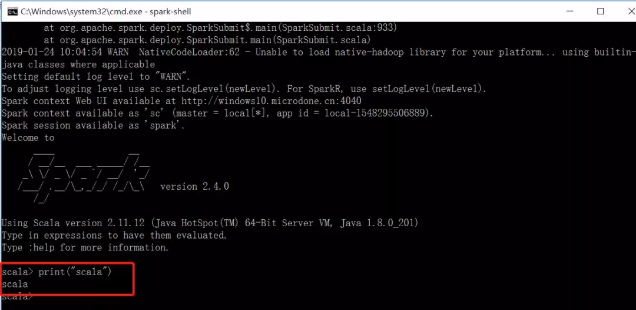
这个时候再次输入sprak-shell就会得到下图中大大的一个spark图案,当你看到这个界面时,说明spark已经安装配置完成了。
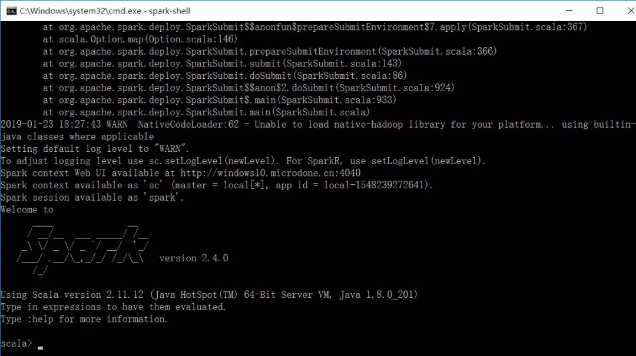
因为spark是由scala语言写的,所以spark原生就支持scala语言,所以你会看到scala>这个符号,scala语言中也有print方法,我们输入一个看看结果,得到我们想要的结果了,说明正式安装完成了。
5.PySpark安装
经过上面的步骤以后我们算是把spark已经成功安装到了我们的电脑中,但是spark默认是用的scala语言。如果我们想要用Python语言去写spark的话,而且只需要用Python语言的话,可以直接利用pyspark模块,不需要经过上面的spark下载和环境配置过程,但是同样需要java环境配置过程。pyspark模块安装的方法与其他模块一致,直接使用下述代码即可:
pip install pyspark
这里需要注意一点就是,如果你的python已经添加到环境变量了,那么就在系统自带的cmd界面运行pip。如果你是用的是Anaconda,且没有添加环境变量,那你就需要在Anaconda Promt中运行pip了。当pip安装成功以后,打开jupyter notebook输入:
import pyspark
如果没有报错,说明pyspark模块已经安装成功,可以开始使用啦。
End.爱数据网专栏作者:张俊红作者介绍:一个数据科学路上的学习者、实践者、传播者个人公众号:俊红的数据分析之路
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论