数据挖掘 Wide & Deep与DeepFM模型 本文主要针对排序任务,介绍两种排序模型:Wide & Deep 和 DeepFM。原本打算将两个模型分开单独成文,后来考虑到内容上的相关性,就将这两种模型写在一起了。 zh 26文章 0评论 更多 2020-04-18 1,781 评论 阅读全文
数据挖掘 FM算法原理分析与实践 本文将介绍一种用于推荐系统排序阶段的方法FM,全称Factorization Machines,该算法的目的是解决稀疏数据下的特征组合问题,被广泛应用于广告推荐等CTR预估场景。关... zh 26文章 0评论 更多 2020-04-18 1,442 评论 阅读全文
第五章 Python爬虫:常用浏览器的useragent 在写python网络爬虫程序的时候,经常需要修改UserAgent,比如:不同Agent下看到的内容不一样,比如,京东网站上的手机版网页和pc版网页上的商品优惠不一样。 华天清 9文章 0评论 更多 2020-04-18 数据挖掘 12,064 评论 阅读全文
数据挖掘 机器学习算法比较 机器学习算法太多了,分类、回归、聚类、推荐、图像识别领域等等,要想找到一个合适算法并不容易,所以在实际应用中,如果只在寻找一个"足够好"的算法来解决问题,下面来分析下各个算法的优缺... zh 26文章 0评论 更多 2020-04-18 1,314 评论 阅读全文
数据挖掘 第九章 Python爬虫实战(2):爬取京东商品列表 在上一篇《Python爬虫实战:爬取Drupal论坛帖子列表》,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容。 华天清 9文章 0评论 更多 2020-04-17 1,546 评论 阅读全文
数据挖掘 PCA主成分分析Python实现 PCA主成分分析,主要是用来降低数据集的维度,然后挑选出主要的特征。原理简单,实现也简单。关于原理公式的推导,本文不会涉及,你可以参考下面的参考文献,也可以去Wikipedia,这... zh 26文章 0评论 更多 2020-04-17 961 评论 阅读全文
浅谈影评情感分析数据集的构建 针对豆瓣的电影评论数据做了一个比较简单的情感分析,效果不是很好,最近又进行了进一步尝试,发现了一点点关于情感分析数据集的小门道,这里简单的总结下,后续做文本分析,或许还可以使用上。 zh 26文章 0评论 更多 2020-04-17 数据挖掘 1,646 评论 阅读全文

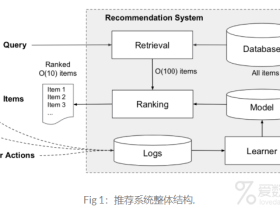 数据挖掘
数据挖掘
数据挖掘
数据挖掘
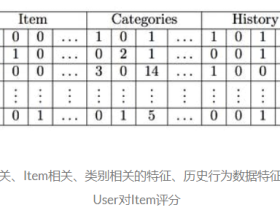 数据挖掘
数据挖掘
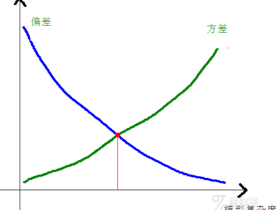 数据挖掘
数据挖掘
 数据挖掘
数据挖掘
 数据挖掘
数据挖掘
评论