
报错会因为每个人的电脑文件以及电脑设置不同而报不同错误,所以报错是无法穷尽的,所以大家需要培养的解决报错的能力,那就是搜索。
 其他
其他
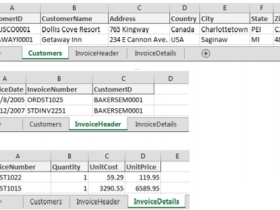
一个跨表透视的例子告诉你为什么要学PowerPivot
使用PowerPivot的第一步就是将数据加载到PP模型中。而将数据加载的PP中可以有两种形式从外部数据源加载或者从当前Excel工作簿加载。本文先通过一个例子讲讲如何将当前工作表...
 其他
其他
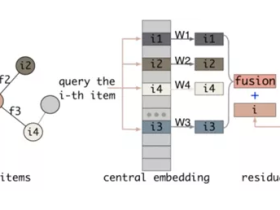
推荐系统之未登录特征值处理
就像一个中国人,我们每个人都会对应一个身份证号,在有关个人的档案信息库里面,输入身份证号,个人的基本信息比如年龄、性别、身高等信息就可以查询得到,我们可以将FeatureID类比身...
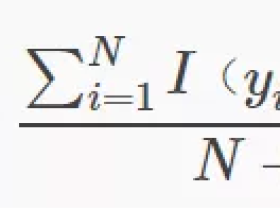 其他
其他
机器学习第三篇:详解朴素贝叶斯算法
朴素贝叶斯算法就是根据贝叶斯公式来对未知事物进行分类,通过已知条件(X=x)计算未知事物分别属于各个类别(Y=ck)时对应的概率,然后把未知事物判别为概率最大的那一类。
使用Python生成自动报表(Excel)以邮件发送
数据分析师肯定每天都被各种各样的数据数据报表搞得焦头烂额,老板的,运营的、产品的等等。而且大部分报表都是重复性的工作,这篇文章就是帮助大家如何用Python来实现报表的自动发送,解...
 其他
其他
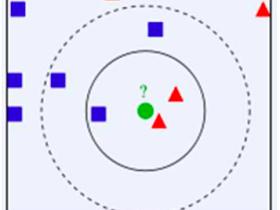
机器学习第二篇:详解KNN算法
本篇介绍机器学习众多算法里面最基础也是最"懒惰"的算法——KNN(k-nearest neighbor)。你知道为什么是最懒的吗?
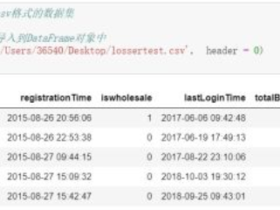 其他
其他
利用深度学习建立流失模型
失去一个老用户会带来巨大的损失,大概需要公司拉新10个新用户才能予以弥补。如何预测客户即将流失,让公司采取合适的挽回措施,是每个公司都要关注的重点问题。
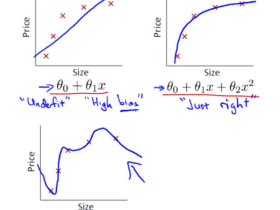 其他
其他
机器学习第一篇:开篇
统计学习的作用是对数据进行预测与分析,特别是对未知数据进行预测与分析,而对数据的预测与分析是通过构建概率统计模型来实现的。所以统计学习的目的是学习什么样的模型和如何学习模型,来让模...
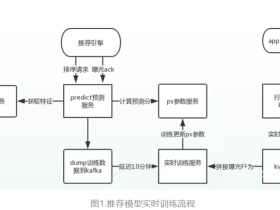 其他
其他
如何构建一个信息流推荐排序系统
推荐排序在一个推荐系统当中的重要性毋庸赘言,本文主要结合本人实际工作,跟大家探讨一下构建一个信息流推荐排序系统值得思考的一些问题。
 其他
其他
爬取了中国的米其林餐厅数据之后..
首版北京米其林指南在 2019 年 11 月 28 日 发布了,但却引起了不小的争议。不少北京网友认为在家门口都不会去的餐厅竟然被评为米其林?这是翻车指南吗?
评论