
一.先看一个案例
对于男性而言,个人职位是否与吸烟有关,假设有人收集了这样的一组数据,如下:
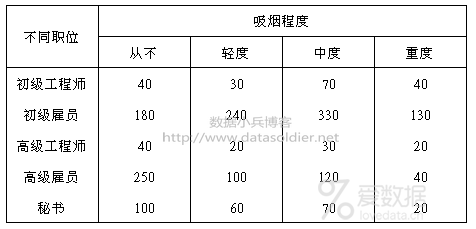
数字表示人数,仅从交叉表内数据大小按照热度区分的话,效果大概是这个样子,红色越深的格子表示人数越多:
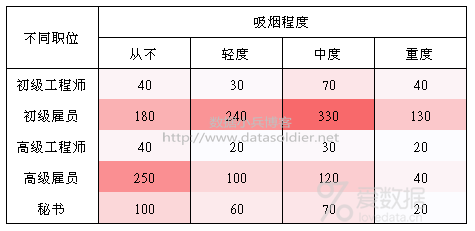
我们发现初级雇员普遍吸烟,中度最多,其他的表现并不明显,总体上很难发现什么规律。 除了热图之外,还可以考虑常见的条形图,效果如下:
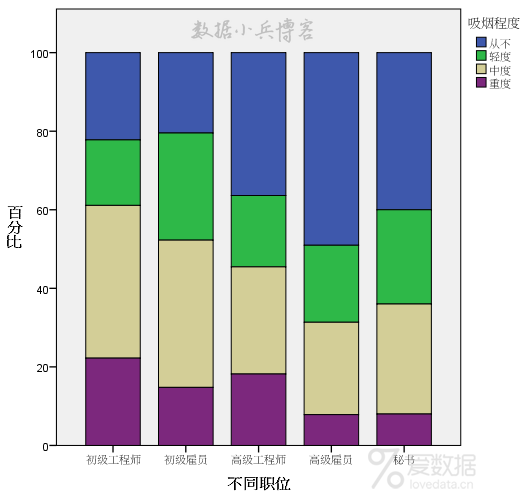
可视化的效果要比前面热图好很多,给人的直观感觉是,职位较高的男性,重度吸烟的比例较低,多数从不吸烟。 经过以上两种图示化方法的预处理,我们能从其中总结职位和吸烟关系的把握并不大。
二.SPSS交叉表卡方检验
熟悉SPSS统计分析的人可能还会想到,是否可以先采用交叉表卡方检验来观察职位和吸烟之间的关系呢?
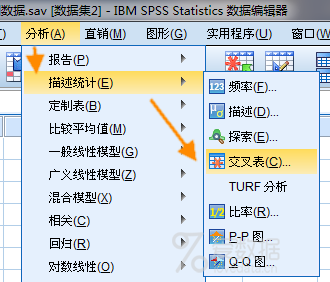
在SPSS的数据视图下,对数据按频数变量进行加权,然后依次点击【分析】→【描述统计】→【交叉表】,在【交叉表:统计】对话框内勾选【卡方】,其他参数默认设置。来看结果:
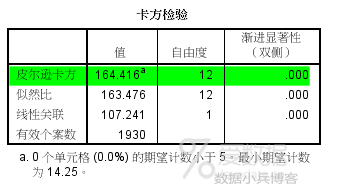
原假设职位和吸烟两个变量间相互独立,渐进显著性小于0.01,说明两个变量间不完全独立,不同职位其吸烟程度有着显著差别。 卡方检验的结果给我们吃下一颗放心丸子,职位和吸烟之间的关系值得深入研究,但它们之间的关系到底应该如何描述呢?前面尝试的热力图、条形图、交叉表卡方检验均没有给出完美结论。
三.SPSS简单对应分析
步骤1:案例数据导入SPSS软件
SPSS对应分析对数据的要求是按变量存储,一般包括三个变量,两个名义变量和一个频数变量,如果原始数据在Excel文件中是一个二维表,需要首先将其转换为一维表格,再导入SPSS软件。 数据较少时,最简单的方法就是复制粘贴,也可以快速实现二维表转一维表。不管如何处理,最终导入SPSS的数据文件长这样:
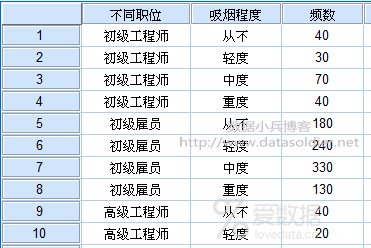
步骤2:数据加权
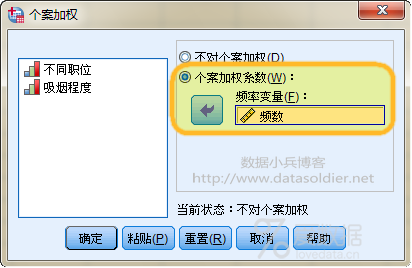
我们的分析任务是搞清楚职位和吸烟程度两个名义变量的关系,要对他们进行量化考察,需要用频数数据加权,SPSS数据视图下,依次点击菜单【数据】→【个案加权】,将频数数据移入右侧【频率变量】框内,对职位和吸烟两个变量进行加权。 步骤3:对应分析主面板参数设置

菜单栏中依次点击【分析】→【降维】→【对应分析】,打开对应分析主面板,依次将【不同职位】【吸烟程度】两个名义变量移入行和列框内。
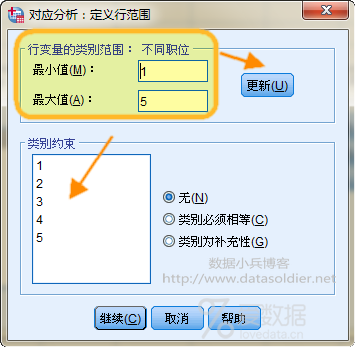
点击下方【定义范围】按钮,以定义行范围为例,行变量【不同职位】有5个分类水平,标签值从小到到依次为1-5,所以最小值输入数字"1",最大值输入数字"5",然后点击右侧【更新】按钮,此时下方的【类别约束】框内自动出现1-5一个序列,类似操作,完成对列变量范围的定义。点击【继续】返回主面板。
步骤4:对应分析模型参数设置
在主面板上点击【模型】按钮,打开模型对话框。

一般默认采取2维,距离测量勾选【卡方】。对应分析也是一种降维技术,通常选择在一个二维表和二维图形中考察分类变量间的关系。 行和列变量间的距离测度软件默认选择【卡方】,当用卡方测量距离时,SPSS软件只默认选择【除去行列平均值】作为标准化方法。 最底部的【正态化方法】相对比较复杂,理解起来有一定难度,建议选择软件默认选项【对称】,检查两个变量分类间的差异或相似。 点击【继续】按钮,返回主面板。 步骤5:对应分析统计参数设置
软件默认勾选【对应表】【行点概述】【列点概述】,点击【继续】按钮,返回主面板。 步骤6:对应分析图参数设置
对应分析最重要的结果之一,就是对应图,主面板上点击【图】按钮,打开图对话框,散点图选项中默认勾选【双标图】,也就是我们最终想要的对应图了。其他默认设置,点击【继续】按钮,返回主面板。 最后在主面板中点击【确定】按钮,SPSS软件开始执行对应分析。
四.SPSS对应分析结果解读
结果1.对应表
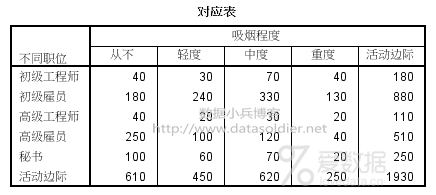
对应表实际上就是交叉表,行与列交叉的单元格显示为频数,行与列的活动边际,具体为对应行和列的和。对应表看看即可,了解一下,不用深究。
结果2.模型摘要表
模型摘要表是关键结果之一,重点考察。
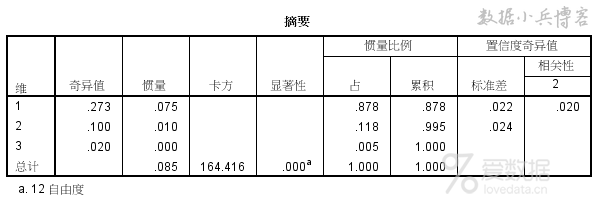
此表类似于因子分析的总方差表,第一列【维】较抽象,可以理解为因子分析的因子,第2-5列分别为奇异值、惯量、卡方值及sig值,随后给出各个维度所能解释两个变量关系的百分比。 首先来看卡方检验的结果,卡方值=164.416,显著性Sig值=0.000<0.01,表明此次分析的两个名义变量,职位和吸烟程度不完全独立,存在一定关系,这和前面交叉表卡方检验结果一致。 卡方检验通过之后,再来解读对应分析的其他结果更有意义。 摘要表数据表明,前两个维度累积惯量可解释99.5%的信息,效果非常不错,此次分析较成功。 结果3.行/列点总览
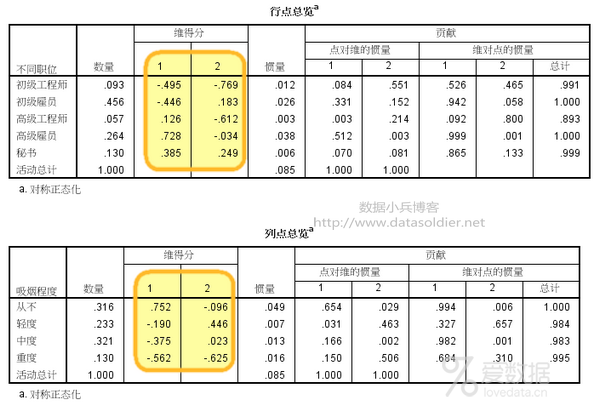
这两个表格,主要输出各类别在各维度上的得分,后续最重要的对应图,将依据这两组维度得分进行绘制。
结果4.对应图
对应分析关键结果之一,重点考察。
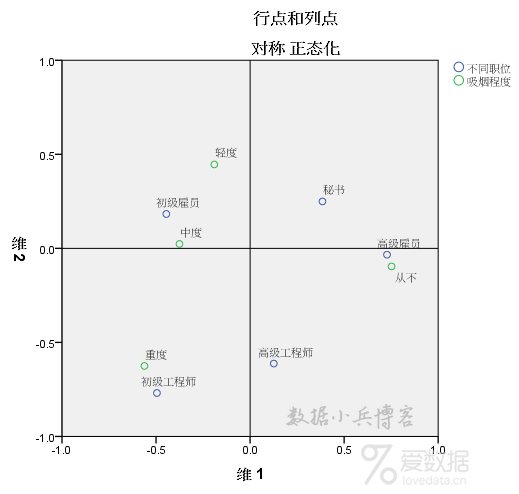
模型摘要表中,我们已经确认前两个维度解释能力很棒,那么SPSS软件默认将采用这两个维度的得分制作二维散点图,也就是现在的对应图。 此时我们可以看到,不同职位的5个类别和吸烟程度的4个类别被标记为不同的颜色进行区分,职位点和吸烟点间距离有远有近,距离的远近包含了它们之间的关系。 总体观察来看,容易发现初级雇员和中度距离较近,可以理解为初级雇员多为中度吸烟;而高级雇员和从不吸烟的距离比较近,说明高级别雇员很少吸烟。此外职别最低的初级工程师和重度吸烟较近,说明这个级别的职工重度吸烟居多。 沈浩老师博客和小蚊子数据分析博客曾对对应分析对应图的解读做过总结,一共有7种解读的方式,按照四象限以及市场定位的方法,本例分析的对应图可以作出如下优化:
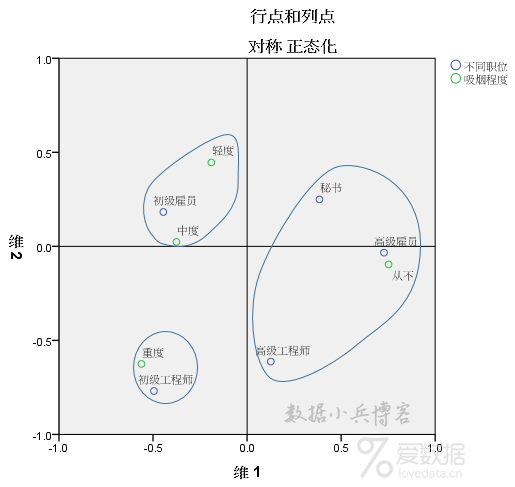
以维度1原点为界,吸烟程度中的轻度、中度、重度均在左侧,而从不吸烟则单独出现在右侧,说明从不吸烟和其他三种类别区别较大,与此对应的是,高级工程师和高级雇员这三个职位也集中在右侧,可以理解为职别较高的人最有可能是从不吸烟。采用同样的方式,容易发现,初级雇员与轻度和中度吸烟距离较近,职别最低的初级工程师与重度吸烟距离近,这和总体观察时的结论一致。
End.作者:数据小兵来源:博客本文均已和作者授权,如转载请与作者联系。
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论