
前言
很多网友在后台跟我留言,是否可以分享一些爬虫相关的文章,我便提供了我以前写过的爬虫文章的链接(如下链接所示),大家如果感兴趣的话也可以去看一看哦。在本文中,我将以智联招聘为例,分享一下如何抓取近5000条的数据分析岗信息。
往期爬虫链接
爬虫流程
首先简单聊一下Python抓取互联网数据的一般步骤,如下图所示:
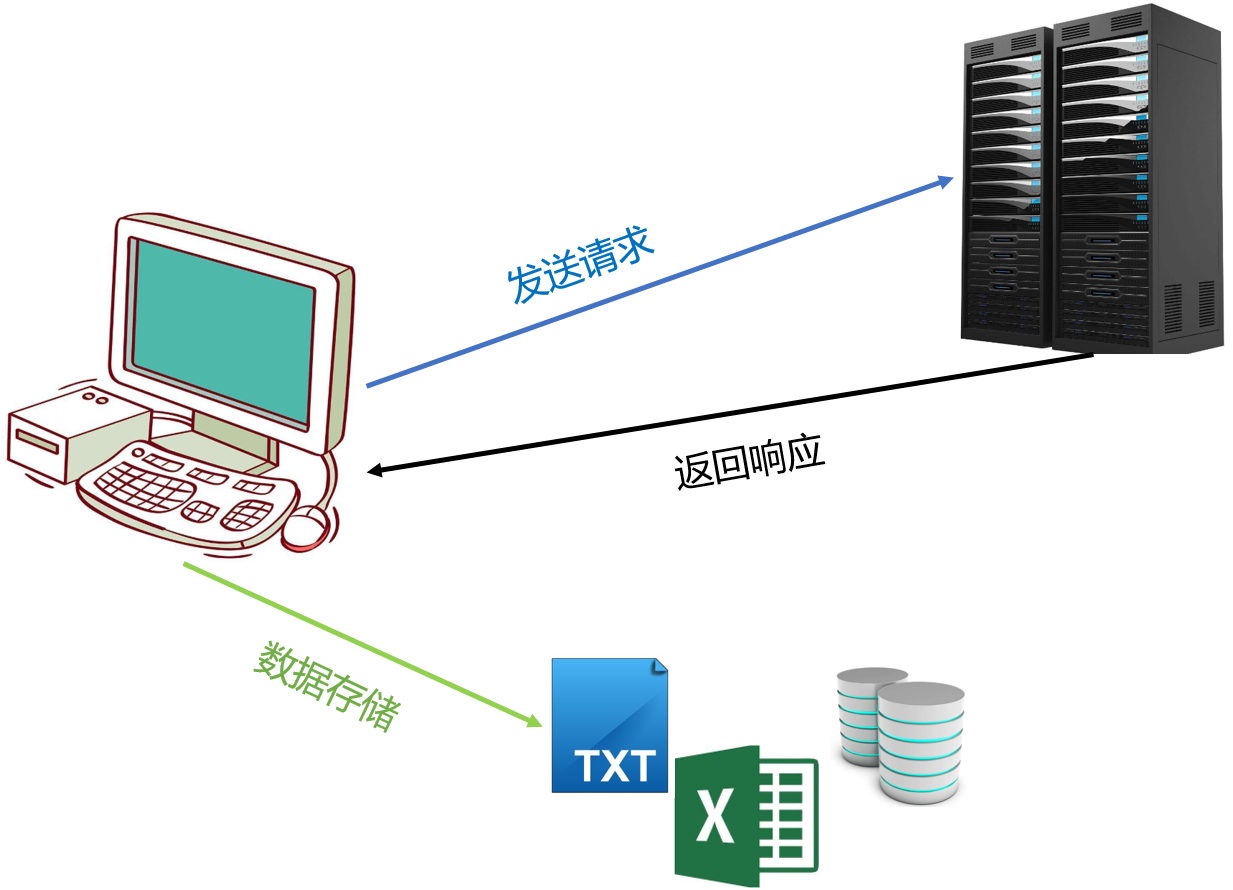
1)发送请求,向对方服务器发送待抓取网站的链接URL;2)返回请求,在不发生意外的情况下(意外包括网络问题、客户端问题、服务器问题等),对方服务器将会返回请求的内容(即网页源代码)3)数据存储,利用正则表达式或解析法对源代码作清洗,并将目标数据存储到本地(txt、csv、Excel等)或数据库(MySQL、SQL Server、MongoDB等)
爬虫实操
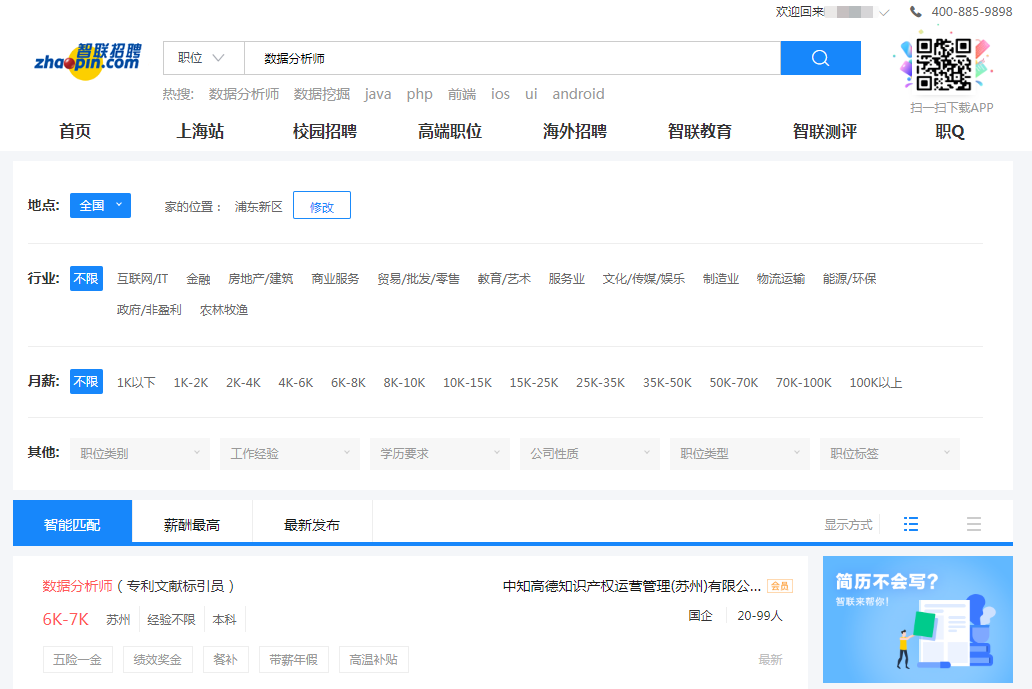
接下来,在理解了爬虫流程之后,我们借助于智联招聘的网站,跟大家分析如何一步一步的完成数据的抓取。寻找目标URL 如下图所示,是在智联招聘网站上搜索"数据分析师"岗位后的响应结果。按照常理,需要按一下键盘中的F12键,对网页内容进行监控。

接着,在原网页中下来滚动条,并点击"下一页",此时右侧的监控台便发生了变化,读者需要按下图进行选择:
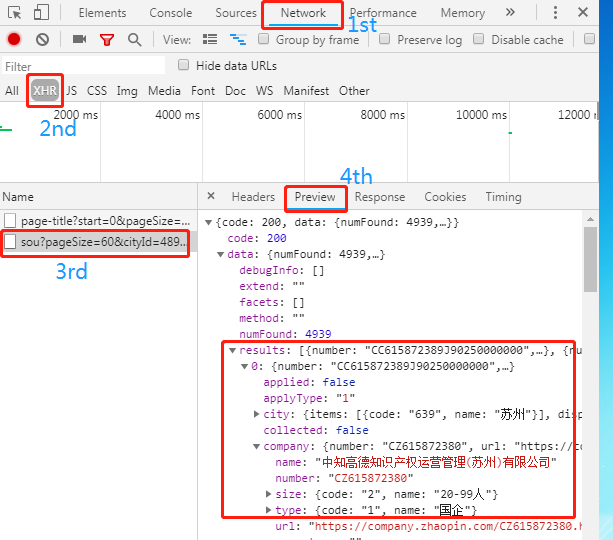
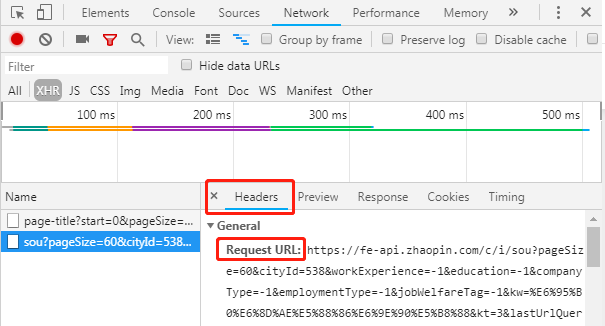
经过这四步的选择,就可以发现招聘网站上的信息都在这个Preview(预览)里面。那么问题来了,需要抓取的URL是什么呢?此时只需点击Headers卡即可,你会发现请求链接就是下图中框出来的部分:
发送请求并返回请求内容 既然找到了目标URL,下面要做的就是基于Python向智联招聘的服务器发送请求了,具体代码如下:
import requests # 用于发送URL请求import pandas as pd # 用于构造数据框import random # 用于产生随机数import time # 用于时间停留# 根据第一页的URL,抓取"数据分析师"岗位的信息url = r"https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3&lastUrlQuery=%7B%22jl%22:%22489%22,%22kw%22:%22%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88%22,%22kt%22:%223%22%7D&at=9c5682b1a4f54de89c899fb7efc7e359&rt=54eaf1be1b8845c089439d53365ea5dd&_v=0.84300214&x-zp-page-request-id=280f6d80d733447fbebafab7b8158873-1541403039080-617179"# 构造请求的头信息,防止反爬虫headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"}# 利用requests包中的get函数发送请求response = requests.get(url, headers = headers)# 基于response返回Json数据datas = response.json()

如上结果所示,即为抓取回来的招聘信息,这些信息是以字典的形式存储起来的。需要说明的是,在发送请求的代码中,添加了请求头信息,其目的就是防止对方服务器禁止Python爬虫。关于头信息可以在Headers选项中的"Request Headers"部分找到,读者只需将"User-Agent"值摘抄下来即可。

内容解析(Json) 下面利用字典的键索引知识,将所需字段的值解析出来。这里不妨以公司名称为例,利用字典的索引技术将其取出来。具体如下图所示:

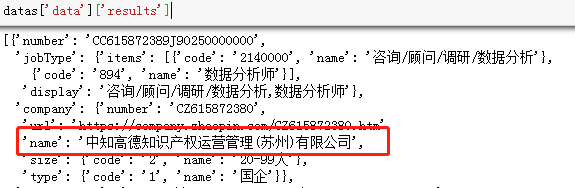
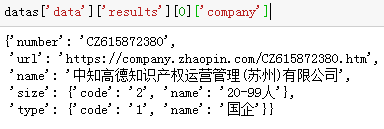

OK,按照如上的策略,便可以取出其他字段的信息,具体代码如下:
# 根据Json数据返回每一条招聘信息# 返回公司名称company = [i["company"]["name"] for i in response.json()["data"]["results"]]# 返回公司规模size = [i["company"]["size"]["name"] for i in response.json()["data"]["results"]]# 返回公司类型type = [i["company"]["type"]["name"] for i in response.json()["data"]["results"]]# 返回公司招聘信息positionURL = [i["positionURL"] for i in response.json()["data"]["results"]]# 返回工作经验的要求workingExp = [i["workingExp"]["name"] for i in response.json()["data"]["results"]]# 返回教育水平的要求eduLevel = [i["eduLevel"]["name"] for i in response.json()["data"]["results"]]# 返回薪资水平salary = [i["salary"] for i in response.json()["data"]["results"]]# 返回工作岗位名称jobName = [i["jobName"] for i in response.json()["data"]["results"]]# 返回福利信息welfare = [i["welfare"] for i in response.json()["data"]["results"]]# 返回岗位所在城市city = [i["city"]["items"][0]["name"] for i in response.json()["data"]["results"]]# 返回经度lat = [i["geo"]["lat"] for i in response.json()["data"]["results"]]# 返回纬度lon = [i["geo"]["lon"] for i in response.json()["data"]["results"]]# 将返回的信息构造表格pd.DataFrame({"company":company,"size":size,"type":type,"positionURL":positionURL, "workingExp":workingExp,"eduLevel":eduLevel,"salary":salary, "jobName":jobName,"welfare":welfare,"city":city,"lat":lat,"lon":lon})
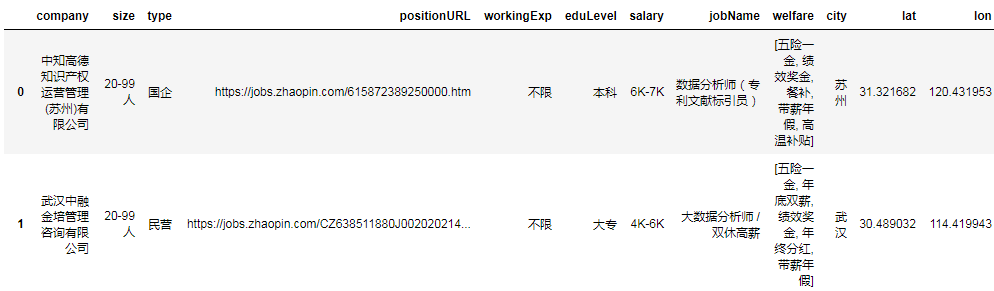
数据存储 如上操作只是将招聘网站中的第一页内容抓取下来,如果需要抓取n多页,就需要借助于for循环的技术。但在循环之前,需要准确找到目标链接的规律,然后使用for循环就水到渠成了。所以,我们按照之前的方法,找到第二页、第三页、第四页链接,然后发现其中的规律,如下图所示:
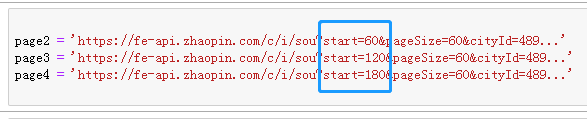
如上图所示,在链接中只有一部分内容发生变化,即"start=",而其他部分都保持不变。所以,按照这个规律就可以对多页内容进行抓取,代码如下:
# 构造空列表,用于存储各页的招聘信息jobs = []# 利用for循环,生成规律的链接,并对这些链接进行请求的发送和解析内容for i in range(0,6001,60): url = "https://fe-api.zhaopin.com/c/i/sou?start="+str(i)+"&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3&lastUrlQuery=%7B%22p%22:5,%22jl%22:%22489%22,%22kw%22:%22%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88%22,%22kt%22:%223%22%7D&at=17a95e7000264c3898168b11c8f17193&rt=57a342d946134b66a264e18fc60a17c6&_v=0.02365098&x-zp-page-request-id=a3f1b317599f46338d56e5d080a05223-1541300804515-144155" response = requests.get(url, headers = headers) print("Down Loading:","https://fe-api.zhaopin.com/c/i/sou?start="+str(i)+"&pageSize=60","......") company = [i["company"]["name"] for i in response.json()["data"]["results"]] size = [i["company"]["size"]["name"] for i in response.json()["data"]["results"]] type = [i["company"]["type"]["name"] for i in response.json()["data"]["results"]] positionURL = [i["positionURL"] for i in response.json()["data"]["results"]] workingExp = [i["workingExp"]["name"] for i in response.json()["data"]["results"]] eduLevel = [i["eduLevel"]["name"] for i in response.json()["data"]["results"]] salary = [i["salary"] for i in response.json()["data"]["results"]] jobName = [i["jobName"] for i in response.json()["data"]["results"]] welfare = [i["welfare"] for i in response.json()["data"]["results"]] city = [i["city"]["items"][0]["name"] for i in response.json()["data"]["results"]] lat = [i["geo"]["lat"] for i in response.json()["data"]["results"]] lon = [i["geo"]["lon"] for i in response.json()["data"]["results"]] # 随机生成5~8之间的实数,用于页面的停留时长(仍然是防止反爬虫) seconds = random.randint(5,8) time.sleep(seconds) # 将每一页的内容保存到jobs列表中 jobs.append(pd.DataFrame({"company":company,"size":size,"type":type,"positionURL":positionURL, "workingExp":workingExp,"eduLevel":eduLevel,"salary":salary, "jobName":jobName,"welfare":welfare,"city":city,"lat":lat,"lon":lon}))# 拼接所有页码下的招聘信息jobs2 = pd.concat(jobs)# 将数据导出到Excel文件中jobs2.to_excel("jobs.xlsx", index = False)
如上结果所示,即为数据导出后的Excel效果图。在下一期,我将针对抓取回来的数据,进行内容的分析。
结语
OK,关于使用Python完成招聘网站数据的抓取就分享到这里,如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。关于Python的其他知识(包括数据的清洗、整理、运算、分析、可视化和建模),读者可以查阅我的新书《从零开始学Python数据分析与挖掘》,如果您对书中的内容有任何疑问,都可以联系我。
本文中的代码和数据可以从百度云盘中下载,只需关注"数据分析1480"公众号,并回复"智联招聘"即可
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论