
三、信用评分卡模型构建
1.逻辑回归建模
网格调参
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import GridSearchCV
cv_params ={ "C": np.arange(0.1,1,0.1),"penalty": ["l1", "l2", "elasticnet", "none"],"solver": ["newton-cg", "lbfgs", "liblinear", "sag", "saga"]}model = LogisticRegression()gs = GridSearchCV(estimator=model,param_grid=cv_params,scoring="roc_auc",cv=5,verbose=1,n_jobs=4)gs.fit(X_train_woe,y_train)print("测试集得分:{0}".format(gs.score(X_test_woe,y_test)))# print("每轮迭代运行结果:{0}".format(grid_search.scorer_))print("参数的最佳取值:{0}".format(gs.best_params_))print("最佳模型得分:{0}".format(gs.best_score_))
Fitting 5 folds for each of 180 candidates, totalling 900 fits测试集得分:0.8223083325618374参数的最佳取值:{"C": 0.4, "penalty": "l2", "solver": "liblinear"}最佳模型得分:0.8295380458229852
建模
from sklearn.linear_model import LogisticRegressionother_params = {"C": 0.4, "penalty": "l2", "solver": "liblinear"}LR_model = LogisticRegression(**other_params)LR_model.fit(X_train_woe, y_train)print("变量名:
",list(keep_var_woe.keys()))print("各个变量系数:
",LR_model.coef_)print("常数项:
",LR_model.intercept_)
变量名:["Age", "Dependents", "CreditLoans", "DebtRatio", "OverDue_90days", "MortgageLoans", "AvailableBalanceRatio", "MonthlyIncome"]各个变量系数:[[ 0.32460639 0.60488285 -0.25729929 0.84472115 0.73975662 0.540272750.7871042 0.16668148]]常数项:[-1.37892239]
2.模型评估
模型的评价指标一般有Gini系数、K-S值和AUC值,基本上都是基于评分卡分数的。但是从理论上评分分数是依据预测为正样本的概率计算而得,因此基于这个概率计算的指标也是成立的。下面我们用sklearn库中的函数计算模型的AUC值和K-S值,以此初步判断模型的优劣。
from sklearn.metrics import confusion_matrix,roc_auc_score,roc_curve, auc,precision_recall_curvey_pred_train = LR_model.predict(X_train_woe)y_pred_test = LR_model.predict(X_test_woe)
训练集的混淆矩阵:[[27141 876][ 4657 2326]]测试集的混淆矩阵:[[11598 385][ 2032 985]]
# 预测的分值y_score_train = LR_model.predict_proba(X_train_woe)[:,1] # 通过 LR_model.classes_ 查看哪列是label=1的值y_score_test = LR_model.predict_proba(X_test_woe)[:,1]# 分别计算训练集和测试集的fpr,tpr,thresholdstrain_index = roc_curve(y_train, y_score_train) #计算fpr,tpr,thresholdstest_index = roc_curve(y_test, y_score_test) #计算fpr,tpr,thresholds
AUC值
ROC曲线是以在所有可能的截断点分数下,计算出来的对评分模型的误授率(误授率表示模型将违约客户误评为好客户,进行授信业务的比率)和1-误拒率(误拒率表示模型将正常客户误评为坏客户,拒绝其授信业务的比率)的数量所绘制而成的,AUC值为ROC曲线下方的总面积
# AUC值roc_auc_train = roc_auc_score(y_train, y_score_train)roc_auc_test = roc_auc_score(y_test, y_score_test)print("训练集的AUC:", roc_auc_train)print("测试集的AUC:", roc_auc_test)
训练集的AUC: 0.8297773383440796测试集的AUC: 0.8223083325618374
- 训练集和测试集的AUC值相差不大,没有发生过拟合的情况
我们再绘制训练集的ROC曲线与测试集的ROC曲线
KS曲线
K-S 测试图用来评估评分卡在哪个评分区间能够将正常客户与违约客户分开。根据各评分分数下好坏客户的累计占比,就可完成K-S测试图。
print("训练集的KS值为:{}".format(max(train_index[1]-train_index[0])))print("测试集的KS值为:{}".format(max(test_index[1]-test_index[0])))
训练集的KS值为:0.5117269204064546测试集的KS值为:0.5067980932328976
# ------------------------- KS 曲线---------------------------绘制训练集与测试集的KS曲线
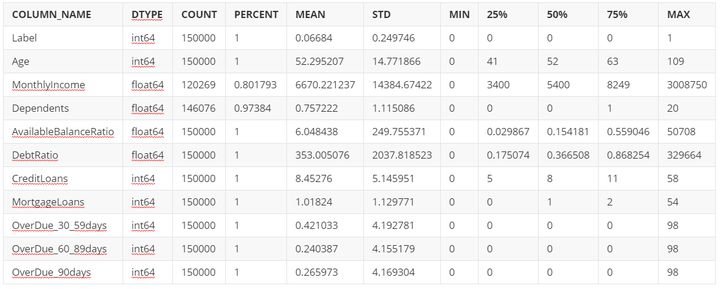
- result: 从AUC值和K-S值来看,我们训练的模型对好坏客户已经具有非常良好的区辨能力了。并且训练集和测试集指标接近,没有发生过拟合的情况。
需要注意的是实际业务中数据需要这样准备:模型开发前,我们一般会将数据分为:训练集train、测试集test、跨时间数据OOT(train和test是同一时间段数据,一般三七分,oot是不同时间段的数据,用来验证模型是否适用未来场景)通过这样的技术保证模型最终可靠稳定。
3.生成评分卡
评分卡输出
# 用自定义的评分卡函数score_scale生成评分卡,参数可见具体的函数r=score_scale(LR_model,X_train_woe,civ_df,pdo=20,score=600,odds=10)# 输出最终的评分卡r.ScoreCard.to_excel("ScoreCard.xlsx",index=False)print("评分卡最大值和最小值区间为:{}".format(r.minmaxscore))
评分卡最大值和最小值区间为:[447, 640]
基于评分的KS值
绘制结果如下:
策略建议
由训练集的KS值可知,570分是好坏样本的最佳分隔点。测试集对其进行验证,KS值为569,基本一致。因此我们可在训练集的KS值上下10分内可做如下策略:
- 580分以上的直接予以通过;
- 560分以上的直接予以拒绝;
- [560,580]之间的人群,可以加入人工判断进行审核。
以上只是我们给出的策略建议,实际问题和需求远比这里复杂,风控人员可以根据具体业务需求给出更加贴合实际业务的策略建议。
4.新数据的预测
数据准备
# 读取预测数据data_predict = pd.read_csv("Predict_data.csv")# 缺失值的处理data_predict["Dependents"].fillna(NOD_median,inplace=True) #用训练集填信息充缺失值data_predict["MonthlyIncome"].fillna(-8,inplace=True)# 异常值的处理:用训练集中的盖帽法极端值处理预测集的异常值for itr in df_min_max.columns:data_predict[itr] = cap2(data_predict[itr],df_min_max)# WOE特征转换for var_name,var_woe in keep_var_woe.items():data_predict[var_woe] = fp.woe_trans(data_predict[var_name], civ_dict[var_name])X_predict_woe = data_predict[keep_var_woe.values()] # train集的WOE特征print("用于预测的数据集经过WOE转换后的shape:{}".format(X_predict_woe.shape))
用于预测的数据集经过WOE转换后的shape:(101503, 8)
预测
# 预测客户的评分结果score_result = score_predict(data_predict,r)# 预测为正样本的概率X_predict_woe = data_predict[keep_var_woe.values()]# 合并评分和概率y_score_predict = LR_model.predict_proba(X_predict_woe)[:,1] # 通过 LR_model.classes_ 查看哪列是label=1的值y_score_predict = pd.Series(y_score_predict).to_frame(name="预测为违约客户的概率")
# 保留用户ID、预测评分和预测概率三列信息,并输出data_predict_score = score_result[["UserID","Score"]].rename(columns={"Score":"预测评分"})predict_result = pd.concat([data_predict_score,y_score_predict],axis=1)# 生成"策略建议"策列cut_off = 570 #切分值f = 10 #上下浮动值fuc = lambda x:"通过" if x>cut_off+f else "拒绝" if x<cut_off-f else "人工介入审核"predict_result["策略建议"] = predict_result["预测评分"].map(fuc)predict_result.to_excel("predict_result.xlsx",index=False)# 输出预测结果to excel
predict_result.head(20) #查看前20行
predict_result.groupby("策略建议").size().to_frame(name="人数统计")
- Result: 这里银行原本需要审批的客户量有105103(=13747+21049+66707。这里经过小王的模型策略,需要人工介入审核的客户量降为13747,只占全部的13.08%。而其中86.92%的客户都能自动决策是通过还是拒绝。
结束语
至此,我们已经用python实现了一个申请评分卡的开发过程,并在结尾给出了策略建议。数据化后的风控极大提高了银行的审批效率,这是传统的人工审核不可比拟的,也正是大数据时代带给我们的便利。
另外需要注意的是,在实际中,模型上线还需要持续追踪模型的表现,一般是每个月月初给全量客户打分,并生成前端和后端监控报告。由于篇幅的原因,在此不做详述,有兴趣的读者可做相关查阅。
End.
作者:CDA数据分析师
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
更多文章前往首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论