
关于数据分析的招聘里,几乎都有"建模"两字的身影。尽管数据分析实际工作中用到机器学习的机会真的不多,但我觉得它仍是数分从业者所需的技能之一。
对于初学者,可能听到机器学习需要线性代数、微积分、概率论、凸优化等数学知识就止步于此,但实际上只要掌握一些较初级的数学知识就能利用机器学习做点事了。、
作为同样零基础过来的我,在学习机器学习过程中遇到非常多的困难,一步步啃过来,目前也算入了个门,近期来重温下这块内容,也想输出点东西,希望能从较白话的方式和大家一起探讨什么是,机器学习。
什么是机器学习?
顾名思义,让机器有学习的能力。
讲宽一点,是让机器通过"某种策略"学习"历史数据"后能够进行一定"预测"的能力。"某种策略"、"历史数据"、"预测"以及这里头N多的专有名词,我将以一个案例逐渐的呈现出来。
小王是某运营商的一名数据分析师,老板最近和他说:"小王啊,最近我们这个xx流量产品每月流失用户都挺多的,能不能帮忙想想办法。"小王思考良久,觉得假设我们能预测出下个月流失用户的名单,那我们是不是能提前对这批用户发发优惠、或者引导他们升级/变更其他流量产品去挽留他们呢?
既然思路有了,那就行动起来。
第一步:确定目标
目的:通过历史数据训练模型使得模型能够预测下个月的流失用户名单。
小王脑海里跳出机器学习的基本术语:
标签:是我们要预测的事务,即简单线性回归中的y变量,在这个案例中,标签即是"下个月某用户是否会流失"。
监督学习:是训练带"标签"的数据去预测的机器学习任务。
无监督学习:是训练不带"标签"的数据去预测的机器学习任务,例聚类。
分类任务:是一种监督学习,机器学习任务的标签为离散型数据,比如本次案例,是否流失,流失为1,留存为0。
回归任务:是一种监督学习,机器学习任务的标签为连续值数据,例子:预测下个月的销售额。
回到本案例来,现在我们可以确定本次任务是一个监督学习里的分类任务,标签是"下个月某用户是否流失"?
第二步:数据准备
数据准备阶段实际上是建模过程中最繁琐的阶段,经常需要去取几十上百张表的数据进行清洗、合并。这个阶段需要理清楚一个概念:数据集划分
当我们取历史数据给模型训练的时候,不是简单的把所有数据丢给模型,模型就能学习出预测的能力,我们往往需要将数据集进行划分:
- 训练集:用于丢给模型进行训练的数据集(一般为全数据60%)
- 验证集:用于优化模型的数据集(一般为全数据10%)
- 测试集:用于评估模型准确性的数据集(一般为全数据30%)
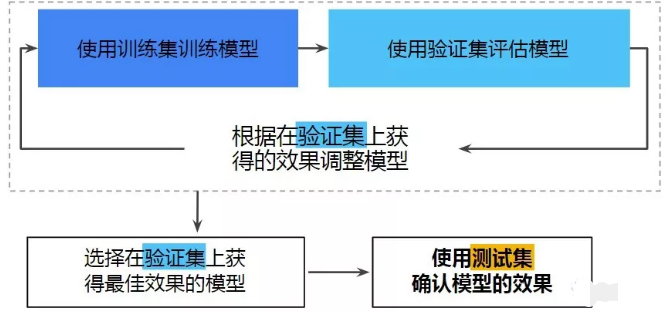
回到本次案例,当前为2019年7月,我想预测8月的流失用户名单,我们应该尽可能多的拿历史数据,假设我们取了近半年的数据。这时我们可以把目标细化为:
通过"近四个月"的历史数据训练模型使得模型能够预测下个月的流失用户名单。这时本次案例的数据集划分为:
- 训练集:2019.1 -2019.4的历史数据
- 验证集:2019.5 的历史数据
- 测试集:2019.6 的历史数据
第三步:模型训练与评估
小王目前已经将数据集准备好了,终于我们可以开始训练模型了,虽然目前机器学习相关的库已经比较成熟,基本把数据一扔就能出结果,但关于模型训练的一些些基本术语我认为还是要了解的。
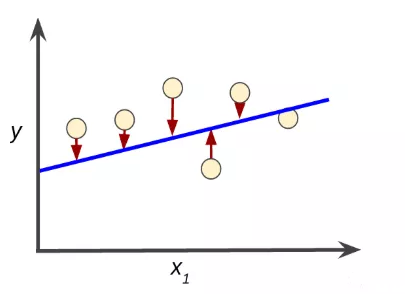
1、损失:简单来说,损失就是模型预测的结果与真实结果的差异。看下图,以线性回归为例,蓝色为模型预测的结果,各个点为真实结果,那么损失就是各红线距离之和。
2、代价函数(也称损失函数):它是我们模型优化的一个方向,告诉模型往哪个方向不断迭代更新。以线性回归为例,假设真实结果为y,模型预测为predcition(x),那么它的代价函数为:
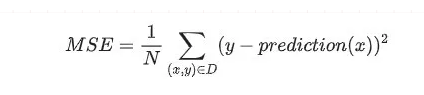
而我们优化的方向就是:模型预测的结果与实际的结果尽可能的吻合,即极可能的减少代价函数。
3、凸优化:一般代价函数是一个凸函数,尽可能的减少代价函数,即意味着我们要找到代价函数趋向于无穷小时的最优解,目前常用的方法有:梯度下降、牛顿法。
4、过拟合:上述一直在强调,代价函数要尽可能的小,但这个小也是有一定界限的,假设到达0,一般是不可取的。代价函数假设非常小,那它说明这个模型在评估的数据集表现得非常好,非常适配该训练集,因为模型过于适配训练集的数据,导致它一般是无法较准确的预测未来的数据,这种现象称为"过拟合"。
5、正则化:我们需要模型预测准确性较高,但又要防止模型过拟合,这咋办比较常用的方法,损失函数加一个正则项,目前常用的正则项有L1、L2正则。
6、泛化能力:指模型对未来数据的预测准确性。
7、模型评估:对于分类、回归、聚类任务的评估指标是不一致的,像上文提到的MSE,是回归的评估指标;
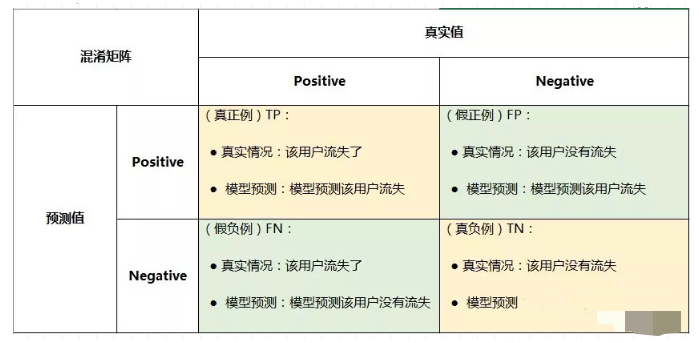
8、交叉验证:基本思想是将多次将原始数据进行分组,一部分作为训练集,一部分作为验证集去评估模型。以著名的K折交叉验证为例:

上图为5折交叉验证:
第一步:将数据集随机均匀的分为5份。
第二步:每次挑选其中一份作为验证集,其余作为训练集用于模型训练。
第三步:用验证集去评估模型得到metric,用模型去预测测试集得到pred
最后能得到5个metric,求和/5就是模型的评估结果,以及5份pred,回归任务求和/5就是测试集的预测结果。分类任务投出最多票数的类别作为测试集的预测结果。
总结
一连串说了很多机器学习术语,现在回到案例来整合一下小王在模型训练及评估阶段做了些啥:
- 用2019.1 – 2019.4月的数据训练了某个分类模型。
- 选择recall和precision作为本次任务的评估指标。
- 用模型去预测训练集、验证集、以及测试集,并用评估指标这三次预测进行评估。
- 判断模型是否过拟合,如果训练集的得分明显高于验证集与测试集,则过拟合。
- 假设过拟合了,用加正则或者交叉验证的方法去避免过拟合。
- 最终输出recall和precision都符合业务标准的模型用于往后预测。
End.
作者:帆软软件
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
更多文章前往首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论