
1SQL简介
SQL全称Structured Query Language,说人话就是结构化查询语言。毫不夸张地说,它是数据分析必会技能Top1,因为没有哪个初级数据分析师的面试能跨过SQL技能考核这一项的。
那么为了更好的理解SQL是什么,与其说它是结构化查询语言,不如称之为查询结构化数据的机器语言。虽然随着发展,SQL的功能已经不限于查询,但是查询语句永远是它的核心。本篇ZZ和大家分享一下他的查询语句SELECT,供大家快速入门SQL。本篇内容框架如下:
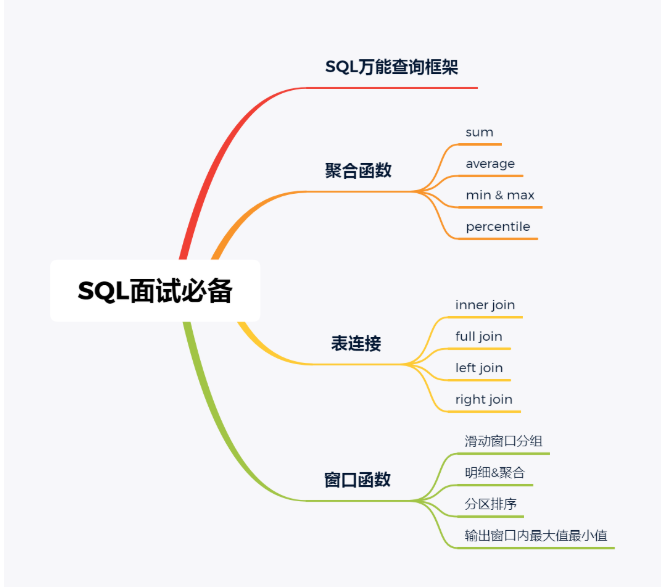
2查询框架
数据分析的第一步是获取数据,在成熟的公司体系中,数据的采集和储存一般有专门的部门来负责,他们可能有不同的名字,例如数据中台,数据仓库等等。数据分析作为数据的消费者,属于数据采集和存储部门的下游。
所以数据分析师主要需要从储存数据的结构化的数据库中提取数据进行分析挖掘,那么工作中使用最多的语句就是SELECT。举个例子,"SELECT"于分析师而言就像"答"对于数学考场上的考生一样,管他什么需求,上来就是一个SELECT准没错。
对于SQL快速入门而言,初学者主要关注三方面的SQL操作即可应付90%的工作,即聚合函数、表连接和窗口函数。
在介绍这些之前,ZZ首先给出SQL操作的一般框架,应用此框架可以应对100%的查询任务,所谓框架已有,胸有成竹。
select [colName_1], [colName_2], ... [colName_n]from [tableName]where [condition]group by [colName]order by [colName]limit [N]对于本框架的作用,举个例子,相当于面临语文阅读题时,回答某个修辞方法的作用:应用了XX的修辞方法,生动形象的描述了XX的场景,抒发了作者XX的思想感情。
简单来说,就是万能的模板,上来就把这个框架CV(Ctrl+C,Ctrl+V)上,再修饰"[]"内的内容即可。
简单解释一下这个框架,紫色部分为关键字,分别代表:
select-查询from-从where-哪里(满足XX条件的)group by-依据XX分组order by-依据XX排序limit-限制N条连起来读就是从XX表中查询满足XX条件的XX列,结果依据XX分组,依据XX排序,限制返回N条。
当然使用框架时依据实际情况灵活将XX换成实际需求的字段,并且这些关键字不是必须都存在的,如只有select和from,让机器知道从哪查询XX也是可以的。下面基于此框架进行进阶学习SQL查询三剑客:聚合函数、表连接和窗口函数。
聚合函数指依据某个规则做合并运算的一系列操作,通俗来讲就是把一列数聚合为一个数的操作,包括求和运算,平均值运算,最大最小值运算,分位点计算等等;
为什么聚合函数比较常用呢?就像讲EXCEL的文章一定要讲数据透视表一样,数据的基本统计数据(例如统计学的五数)是分析师最先关注也是最容易获取的有价值的数据。学习SQL的聚合函数,我们可以通过对比EXCEL的数据透视表来学习。因为ZZ看来SQL的聚合函数EXCEL的数据透视表。

那么使用聚合函数需要注意三要素:聚合函数+group by关键字+having关键字。
(1)聚合函数
聚合函数就是我们希望聚合的方式,例如求和sum()、求平均值avg(),计数count()等等,括号里面的参数就是我们希望计算的目标列,聚合函数具体都有什么,ZZ这里不一一列举,需要时查一下即可,ZZ只谈渔不授鱼。聚合函数类似EXCEL数据透视表中"值"的部分。
(2)group by关键字
group by关键字用于指定依据哪些列计算聚合值,为什么要存在group by关键字呢?是为了更方便的从多维度来呈现数据,以一个学校的成绩单为例,大家不会只关注这个学校的平均成绩,我们可能关注的是该学校不同年级,不同科目,不同班级的平均成绩,那么在这个例子中,年纪,科目,班级字段将在group by关键字后设置。group by关键字类似于EXCEL透视表中的"行"和"列"的部分。
(3)having关键字
having关键字用于筛选出聚合值满足一定条件的数据项,例如我们计算每个同学的语数外三科成绩的平均值,同时想限制平均成绩60分,即可使用having关键字筛选:
having avg(score) >= 60注意,这里的having筛选与EXCEL透视表的筛选并不是一个功能,having是对聚合值的筛选,EXCEL透视表的筛选是对字段的值的筛选,这与SQL中的where关键字实现了一样的功能。总的来说,使用聚合函数的三要素是聚合函数+group by关键字+having关键字。
这里聚合函数是必须存在的。另外还有一点需要注意的是:当计算聚合值时,与聚合值无关的字段不可以出现在SElECT关键字下。因为这会导致一对多,SQL逻辑混乱的情况;我们应用上面说的万能框架+聚合三要素给出一段聚合函数的使用案例:
需求:使用聚合函数实现提取在XX学校XX年纪XX班同学中,语数外三门成绩最小值大于等于60分所有同学姓名
一、万能框架:
select studentNamefrom scoreTablewhere school = "XX学校" grade = "XX班"group by studentName二、聚合三要素:
-
1.聚合函数:min(score) -
2.group by关键字:group by studentName -
3.having关键字:having min(score) >= 60
三、组合最终SQL
select studentNamefrom scoreTablewhere school = "XX学校" grade = "XX班"group by studentNamehaving min(score) >= 60对于单表简单操作,上面的万能框架+聚合函数基本可以涵盖,但是在实际工作中,由于业务复杂性,不可能所有数据都放在一张数据表中,这样会造成资源的浪费。所以我们必须掌握的第二个SQL操作就会联表查询。
记得我们分享EXCEL应用时,第二项技术是VLOOKUP和MATCH(INDEX),这项实用的EXCEL技巧映射到SQL操作就是表的连接。
联表查询结合万能框架就特别容易学习,因为联表查询就是两个万能框架中间加一行连接语句以及末尾加一个连接条件。
连接条件较为简单,这里首先说明,即两个表连接在一起时需要满足的条件,一般为两个表中对应字段的值相等;
对于表的连接语句有四种:内连接inner join、全连接full join、左连接left join、右连接right join。我们来简单理解一下:
-
内连接:基于连接条件,两表都存在的数据将被提取出来显示在同一行; -
全连接:基于连接条件,两表都存在的数据将被提取出来显示在同一行,其他数据也会被提取出来,缺失部分使用空值填充; -
左连接:基于连接条件,左表数据作为标准,右表也存在的数据将与左表显示在同一行,否则将使用空值填充; -
右连接:基于连接条件,右表数据作为标准,左表也存在的数据将与右表显示在同一行,否则将使用空值填充;
内连接和全连接是两个极端,内连接是两者均有才会返回,全连接是不管两者有没有,所有数据都要返回,存在匹配成功就放在同一行的形式;
左连接和右连接看起来有一者是多余的,因为我们可以使用左连接和右连接中的任意一个,同时通过调整表查询的顺序来实现左、右连接的功能,那么为什么还会存在这样多余的函数呢?因为在SQL的查询机制中,前面的表(左表)较小时,查询的效率更高;由于这个潜规则,我们放置数据表的顺序被限制后,才需要这两个不同的连接来实现不同的左、右连接的功能。
下面举个例子来一网打尽表的连接操作:
两张数据表:
1、某班同学信息表:studentInfo字段:name、studentID、sex2、该班同学期末成绩表:studentScore字段:studentID、Math、Chinese、English
需求:该班男生的数学平均值
一、万能框架*2
(select studentIDfrom studentInfowhere sex = "男"group by studentID) boyID(select studentID, Mathfrom studentScoregroup by studentID, Math) mathScore二、表的连接
(select studentIDfrom studentInfowhere sex = "男"group by studentID) boyIDleft join --连接语句,使用左连接,左表是我们关心的中心对象:男同学们(select studentID, Mathfrom studentScoregroup by studentID, Math) mathScoreon boyID.studentID = mathScore.studentID -- 连接条件三、聚合求解
select avg(mathScore.Math) as avgBoyMathScorefrom(select studentIDfrom studentInfowhere sex = "男"group by studentID) boyIDleft join --连接语句,使用左连接,左表是我们关心的中心对象:男同学们(select studentID, Mathfrom studentScoregroup by studentID, Math) mathScoreon boyID.studentID = mathScore.studentID -- 连接条件以上我们学习了SQL的两个基本操作,聚合函数和表的连接。面对基础的任务,我们已经可以满足。但是为了展示出我们的专业素质,有必要学习一下面对一些复杂的统计任务时比较常用的窗口函数。
理解窗口函数,我们首先从字面上理解,顾名思义,这是一个实现在滑动窗口上统计值的操作。何为一个滑动的窗口,即一个小区间,这个小区间可以是固定长度,也可以是可变长度的。
为什么会有窗口函数呢?回忆我们之前介绍的聚合函数,它实现了依据某些维度计算某列聚合值的需求,但是如果想更具体的,需要统计某些维度上某些小区间上的聚合值时,聚合函数显得无能为力.
另外,我们介绍了在使用聚合函数时,与聚合列无关的列不可以出现在SELECT关键字下,如果想要除了聚合列之外的其他明细数据和聚合值同时提取时,聚合函数又不太行了 。那么基于以上的原因呢,以更灵活的设置小区间的方式来计算统计值的窗口函数应运而生,ZZ总结窗口函数主要有以下两个方面的应用,(首先统一说明,over关键字是窗口函数的标志),在某个小区间上:
(1)滑动窗口分组
在已有维度不能满足分析需求时,设置一个滑动窗口,来灵活设置统计区间。设置一个滑动窗口来实现统计值的跨度,即设置当前统计值是从第几行计算到第几行,例如计算移动平均值,累计值等等;
滑动窗口设置方式十分简单,关键字OVER + 关键字ROWS + 计算区间:
OVER(ROWS BETWEEN "起始行" AND "结束行")其中起始行和结束行主要有以下的表示方式:
CURRENT ROW --当前行UNBOUNDED PRECEDING --窗口内第一行UNBOUNDED FOLLOWING --窗口内最后一行[N] PRECEDING --当前行向前N行[N] FOLLOWING --当前行向后N行有了以上5种表示方式,那么任意的窗口都可以设置了。默认情况是第一行到当前行,主要应用于计算累积值:
-- 月份month从小到大排序,计算第一个月到当前月的累积销售额sum(sales) over(order by month) -- 月份month从小到大排序,计算第一个月到当前月的累积平均销售额avg(sales) over(order by month) 通过设置窗口计算移动平均值
-- 计算股票的250日均线 -- IOPV:单位净值avg(IOPV) over(order by day ROWS BETWEEN 249 PRECEDING AND CURRENT ROW)(2)明细&聚合
已有维度不能满足分析需求时,设置滑动窗口可以灵活的开发出一些额外的维度。但是当已有维度已经能满足需求时,窗口函数就没有用武之地了吗?恰恰相反,其中一种情况就是当前维度足够时,我们同时想输出明细值和聚合值时,窗口函数就又派上用场:同时输出明细值和聚合值。
# 统计各年级同学每个人的数学成绩和各年级的数学平均分select grade, studentName, Math, avg(Math) over(partition by grade) as gradeAvgMathfrom [tableName]where [condition]group by [colName]order by [colName](3)分区排序
上面介绍在当前维度足够时,窗口函数的一种应用是明细&聚合值一起出来。但这个聚合值可以发生一些变化,演变为排序值,即窗口函数另一应用:分区排序(明细&次序)。类似于明细&聚合操作,我们直接来看一个例子
统计各年级同学每个人的数学成绩并根据成绩由大到小排序,注意,各年级分开排序
select grade, studentName, Math, RANK() over(partition by grade order by Math desc) as gradeMathOrderfrom [tableName]where [condition]分区排序函数详细区分:
RANK() Over(partition by order by ) -- 非稠密排序:1、1、3、3、5DENSE_RANK() Over(partition by order by ) --稠密排序:1、1、2、2、3ROW_NUMBER() Over(partition by order by ) --纯数排序:1、2、3、4、5(4)其他
窗口函数还有一些输出窗口内第一个值和最后一个值的操作,虽然ZZ感觉这个挺多余的,但是还是列一下,省的大家以为我不知道似的。
# FIRST_VALUE() 和LAST_VALUE(),返回窗口的第一个和最后一个值:FIRST_VALUE(SUM(amount)) OVER (ORDER BY month) LAST_VALUE(SUM(amount)) OVER (ORDER BY month)3小结
ok,最后我们来总结一下。

当我们拿到一个取数的需求时,首先列出我们的万能框架,有了框架之后,就有了思路。
如果需要在某个或者多个维度进行聚合(例如求和,平均值,最大最小值,分位点),这时候需要使用我们的聚合函数,然后注意将这些维度放进group by关键字之后即可;
如果业务比较复杂,单从一个表中无法提供所有的字段,这个时候需要进行表连接,根据之前介绍的不同连接方式的区别即可选择对应表链接方式;
如果业务更复杂一些,比如需要计算移动平均值,分组排序,以及同时想看明细和聚合值得情况下,就需要用到强大的窗口函数了。
掌握以上内容,足以应对数据分析师在日常工作中所面临的所有取数的需求,更小的一些细节比如字符串和日期格式的处理,需要用的时候直接百度就可以了。
End.
作者:数据分析不是个事儿
本文为转载分享,如果涉及作品、版权和其他问题,请联系我们第一时间删除(微信号:lovedata0520)
更多文章前往首页浏览http://www.itongji.cn/
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论