
一、前言
我们知道每个模型都有很多参数是可以调节的,比如SVM中使用什么样的核函数以及C值的大小,决策树中树的深度等。在特征选好、基础模型选好以后我们可以通过调整模型的这些参数来提高模型准确率。每个模型有很多参数,而每个参数又有很多不同的取值,我们该怎么调,最简单的一个方法就是一个一个试。sklearn中提供了这样的库代替了我们手动去试的过程,就是GridSearchCV,他会自己组合不同参数的取值,然后输出效果最好的一组参数。
二、GridSearchCV参数解释
GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’)
estimator:所使用的基础模型,比如svc
param_grid:是所需要的调整的参数,以字典或列表的形式表示
scoring:准确率评判标准
n_jobs:并行运算数量(核的数量 ),默认为1,如果设置为-1,则表示将电脑中的cpu全部用上
iid:假设数据在每个cv(折叠)中是相同分布的,损失最小化是每个样本的总损失,而不是折叠中的平均损失。
refit:默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。
cv:交叉验证折叠数,默认是3,当estimator是分类器时默认使用StratifiedKFold交叉方法,其他问题则默认使用KFold
verbose:日志冗长度,int类型,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出
pre_dispatch:控制job数量,避免job过多出现内存错误
三、GridSearchCV对象
cv_results_:用来输出cv结果的,可以是字典形式也可以是numpy形式,还可以转换成DataFrame格式
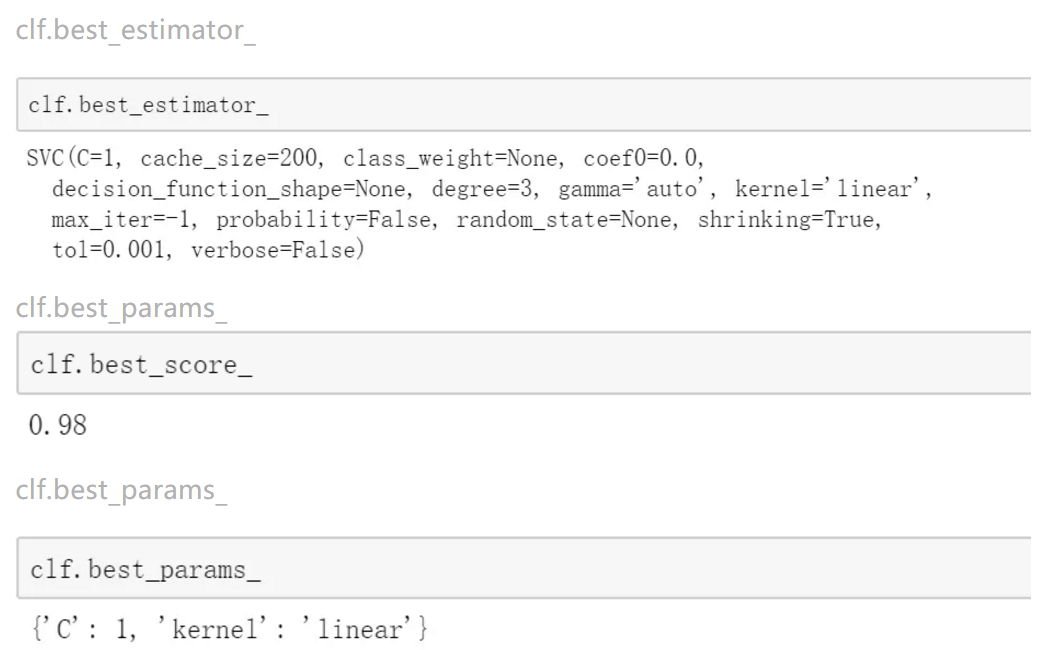
best_estimator_:通过搜索参数得到的最好的估计器,当参数refit=False时该对象不可用
best_score_:float类型,输出最好的成绩
best_params_:通过网格搜索得到的score最好对应的参数
四、GridSearchCV方法
decision_function(X):返回决策函数值(比如svm中的决策距离)
predict_proba(X):返回每个类别的概率值(有几类就返回几列值)
predict(X):返回预测结果值(0/1)
score(X, y=None):返回函数
get_params(deep=True):返回估计器的参数
fit(X,y=None,groups=None,fit_params):在数据集上运行所有的参数组合
transform(X):在X上使用训练好的参数
五、GridSearchCV实例
from sklearn import svm, datasetsfrom sklearn.model_selection import GridSearchCViris = datasets.load_iris()parameters = {"kernel":("linear", "rbf"), "C":[1, 10]}svc = svm.SVC()clf = GridSearchCV(svc, parameters)clf.fit(iris.data, iris.target)------------------------------------------------------GridSearchCV(cv=None, error_score="raise", estimator=SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape=None, degree=3, gamma="auto", kernel="rbf", max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False), fit_params={}, iid=True, n_jobs=1, param_grid={"kernel": ("linear", "rbf"), "C": [1, 10]}, pre_dispatch="2*n_jobs", refit=True, return_train_score=True, scoring=None, verbose=0)
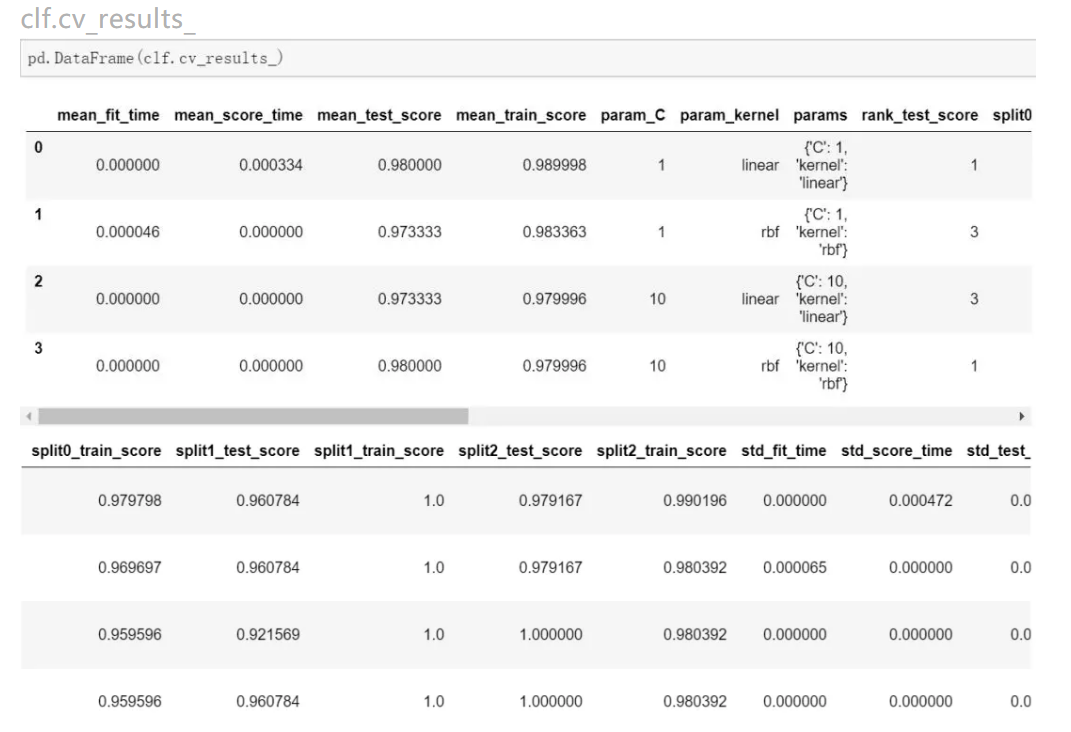
我们可以看到,cv_result一共有四组,这正是两个kernel和两个C的随机组合成四组。
注:本方法只适用于数据量较小的模型,不适合数据量过大的模型。
End.
爱数据网专栏作者:张俊红
作者介绍:一个数据科学路上的学习者、实践者、传播者
个人公众号:俊红的数据分析之路
本文为挖数网专栏作者原创文章,未经允许禁止转载,需要转载请微信联系授权(微信号:lovedata0520)
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论