
本篇节选自书籍《对比Excel,轻松学习SQL数据分析》一书,主要讲解数据分析面试中常见的30道SQL面试题。
11 行列互换
现在我们有下面这么一个表row_col_table,这个表中每年每月的销量是一行数据:
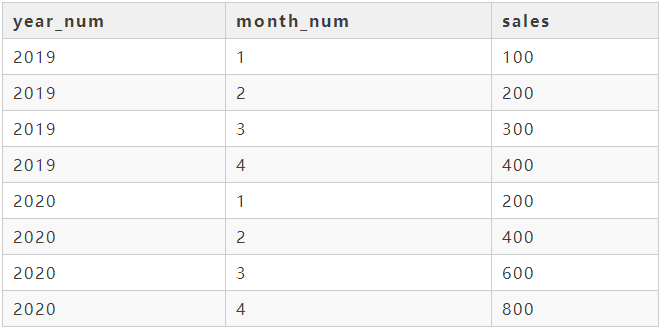
我们需要把上面这种纵向存储数据的方式改成下表所示的横向存储:

自己先想一下代码怎么写,然后再参考我的代码。
select year_num ,sum(case when month_num = 1 then sales end) as m1 ,sum(case when month_num = 2 then sales end) as m2 ,sum(case when month_num = 3 then sales end) as m3 ,sum(case when month_num = 4 then sales end) as m4from demo.row_col_tablegroup by year_num
解题思路:
我们要把纵向数据表转换成横向数据表,首先是把多行的年数据转化为一年是一行,可以通过group by实现;group by一般需要与聚合函数一起使用,但是不是对所有数据进行聚合,所以我们通过case when来达到对指定月份数据进行聚合。
12 多列比较
现在表col_table中有col_1、col_2、col_3三列数据,我们需要根据这三列数据生成最后一列结果列,结果列的生成规则为:如果col_1大于col_2时选col_1列,如果col_2大于col_3列时选col_3列,否则选col_2列。
col_table表如下所示:
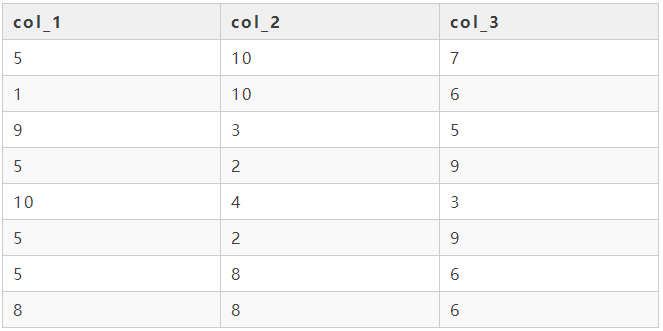
自己先想一下代码怎么写,然后再参考我的代码。
select col_1 ,col_2 ,col_3 ,(case when col_1 > col_2 then col_1 when col_2 > col_3 then col_3 else col_2 end) as all_resultfrom demo.col_table
解题思路:
这个多列比较其实就是一个多重判断的过程,借助case when即可实现,先去判断col_1和col_2的关系,然后再去判断col_2和col_3的关系。这里需要注意一下各判断的执行顺序,先去执行第一行case when,然后再去执行第二行的。最后运行结果如下:
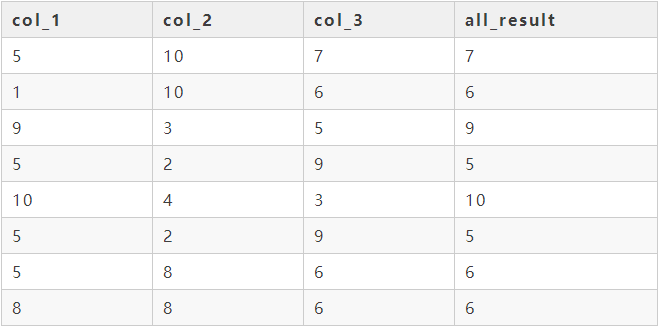
13 对成绩进行分组
现在有一个某科目的学生成绩表subject_table,这张表存储了每位学生的id、score(成绩)以及其他信息,我们想知道60分以下、60-80分、80-100分这三个成绩段内分别有多少学生,该怎实现呢?
subject_table表如下所示:

自己先想一下代码怎么写,然后再参考我的代码。
select (case when score < 60 then "60分以下" when score < 80 then "60-80分" when score < 100 then "80-100分" else "其他" end) as score_bin ,count(id) as stu_cntfrom demo.subject_tablegroup by (case when score < 60 then "60分以下" when score < 80 then "60-80分" when score < 100 then "80-100分" else "其他" end)
解题思路:
我们现在需要知道每个成绩段内的学生数,需要做的第一件事就是对成绩进行分段,利用的就是case when,对成绩分段完成以后再对分段结果进行group by,然后再在组内计数获得每个分段内的学生数。最后运行结果如下:
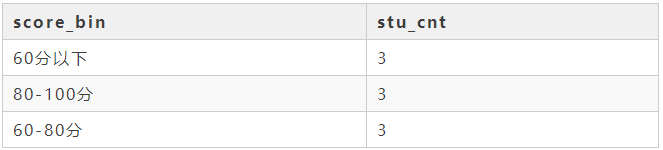
14 周累计数据获取
现在我们有一个订单明细表order_table,这张表中存储了order_id(订单id)、order_date(订单日期)以及其他订单相关信息,现在我们需要每天获取本周累计的订单数,本周累计是指本周一到获取数据当天,比如今天是周三,那么本周累计就是周一到周三。这个该怎么实现呢?
order_table表如下所示:

自己先想一下代码怎么写,然后再参考我的代码。
select curdate() ,count(order_id) as order_cntfrom demo.order_tablewhere weekofyear(order_date) = weekofyear(curdate()) and year(order_date) = year(curdate())
解题思路:
我们是要获取本周累计的订单数,只需要把本周的订单明细筛选出来,然后对订单id进行计数就是我们想要的。那该怎么把本周的订单明细筛选出来呢?让订单日期所属的周与程序运行当日所属的周是一个周,且所属的年是同一年。后面这个条件一定要注意,因为周数在不同年份是会重复的,但是在同一年内是不重复的。比如2019年有一个52周,2020年也会有,但是不会在一年里面出现两个52周。最后运行结果如下:

15 周环比数据获取
我们现在需要根据订单明细表order_table,获取当日的订单数;当日的环比订单数,即昨天的数据。
自己先想一下代码怎么写,然后再参考我的代码。
select count(order_id) as order_cnt ,count(if(date_sub(curdate(),interval 1 day) = order_date,order_id,null)) last_order_cntfrom demo.order_table
解题思路:
当日的订单数比较好获取,主要是环比数据的获取,当订单日期等于当日日期向前偏移1天的日期时,对order_id进行计数就是昨日的订单数。这里面需要注意的是,当if条件不满足时,结果为null,而不能是别的,因为count(null)=0,而count()其他内容不等于0。最后运行结果如下:

16 查找获奖同学信息
现在有一张学生信息表table1,这张表记录了id、name等一些其他信息;还有另外一张获奖名单表table2,这张表记录了获奖学生的id和name。现在我们想要通过table1获取获奖学生的更多信息。
table1表如下所示:

table2表如下所示:

自己先想一下代码怎么写,然后再参考我的代码。
select table1.*from demo.table1left join demo.table2 on table1.id = table2.idwhere table2.id is not null
解题思路:
我们要获取获奖同学的全部信息,已知table1表中存储了全部学生的全部信息,我们用table1去左连接table2,如果该同学有获奖,就会在table2中能找到,反之则找不到。所以我们就可以利用table2的id是否为空来判断该同学有没有获奖,进而把我们想要的信息通过where条件筛选出来。最后运行结果如下:
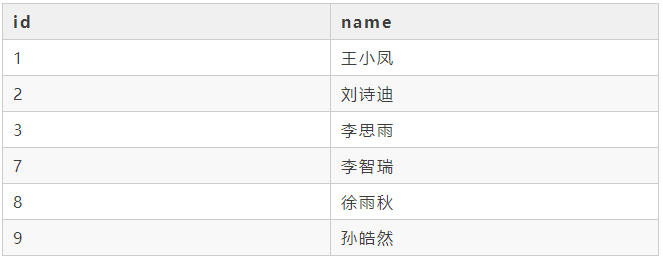
17 计算用户留存情况
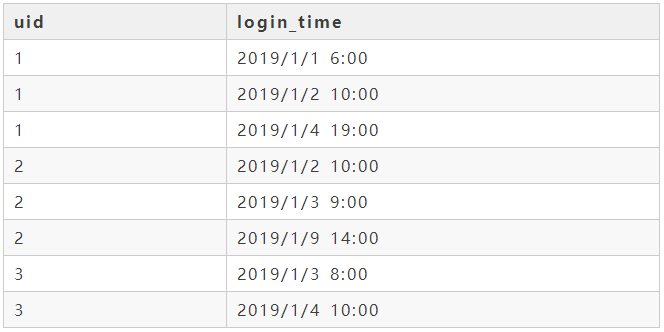
现在有一张用户登陆表user_login,这张表记录了每个用户每次的登陆时间,uid(用户id)和login_time(登陆时间)。我们想看用户的次日留存数、三日留存数、七日留存数,只要用户从首次登陆以后再有登陆就算留存下来了,该怎么实现呢?
user_login表如下所示:
自己先想一下代码怎么写,然后再参考我的代码。
select (case when t3.day_value = 1 then "次日留存" when t3.day_value = 3 then "三日留存" when t3.day_value = 7 then "七日留存" else "其他" end) as type ,count(t3.uid) uid_cntfrom (select t1.uid ,t1.first_time ,t2.last_time ,datediff(t2.last_time,t1.first_time) day_value from (select uid ,date(min(login_time)) as first_time from demo.user_login group by uid)t1 left join (select uid ,date(max(login_time)) as last_time from demo.user_login group by uid)t2 on t1.uid = t2.uid)t3group by (case when t3.day_value = 1 then "次日留存" when t3.day_value = 3 then "三日留存" when t3.day_value = 7 then "七日留存" else "其他" end)
解题思路:
留存是指用户用户从首次登陆以后再有登陆就算留存下来,不同时长的留存表示这么时长以后仍会再次登陆,比如三日登陆表示用户自首次登陆以后第三天也会进行登陆。我们现在要计算不同留存时长的用户数,首先需要计算不同用户的留存时长,可以用该用户的最后一次登陆时间与首次登陆时间做差就是该用户的留存时长,然后再对留存时长进行分组聚合就得到了我们想要的不同留存时长的用户数。最后运行结果如下:
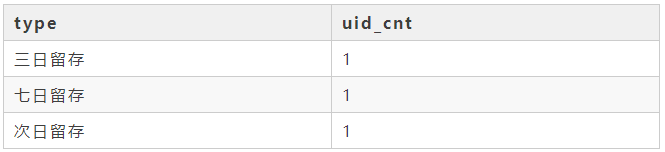
18 筛选最受欢迎的课程
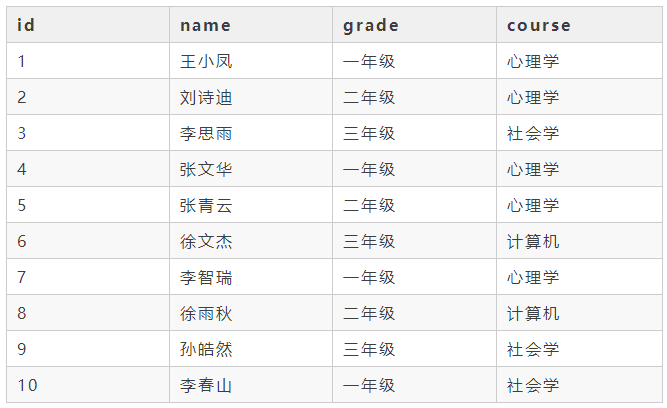
现在有一张学生科目表course_table,这张表存储了每一位学生的id、name(姓名)、grade(年级)、course(选修课程)以及一些其他信息,现在我们想知道哪门课被学生选的人数最多?
course_table表如下所示:
自己先想一下代码怎么写,然后再参考我的代码。
select course ,count(id) as stu_numfrom demo.course_tablegroup by courseorder by count(id) desclimit 1
解题思路:
我们是要获取被选人数最多的课程,首先需要对课程进行分组,使用的是group by;然后再对组内人数进行计数,即选择该课程的人数,使用的count;然后再对课程人数进行降序排列,使用的是order by;最后把排在第一的课程筛选出来,就是我们要的被选择人数最多的课程。最后结果如下:

想一下上面这种思路是否有问题呢?如果要是有两门或者多门课程的选择人数一样多的时候上面的这种思路得出来的结果是否还正确呢?显然是不正确的。
现在再想一下,如果有多门课程选择人数一样多时怎么办?先想一下再看我的思路。
select course ,count(id) as stu_numfrom demo.course_tablegroup by coursehaving count(id) = (select max(stu_num) from (select course ,count(id) as stu_num from demo.course_table group by course )a )
解题思路:
如果存在被选择一样多的课程,我们要把一样多的课程全部筛选出来。首先我们还是需要把每门课程以及被选择的人数获取出来,获取思路与第一种思路是一样的,也是针对课程进行group by,然后再针对组内的人数进行计数;不同点在于最多人数获取上。第一种思路是默认选择人数最多的课程只有一个,而第二种思路是假设选择人数最多的课程有多个时,我们就需要把选择人数最多的人数算出来,这里利用子查询去生成;最后再利用having对分组后的结果进行筛选,从而得到选择人数最多的课程。
19 筛选出每个年级最受欢迎的三门课程
还是前面的course_table,现在我们想知道每个年级被选择最多的三门课程,该怎么实现呢?
自己先想一下代码怎么写,然后再参考我的代码。
select *from (select grade ,course ,stu_num ,row_number() over(partition by grade order by stu_num desc) as course_rank from (select grade ,course ,count(id) as stu_num from demo.course_table group by grade ,course )a )bwhere b.course_rank < 4
解题思路:这是典型的获取组内排名的问题,我们前面的一个问题是获取报名人数最多的课程,只需要把每门课程的报名人数获取到,然后把最多的一个取出来就是我们想要的。可是现在这个问题不仅要获取最多的,还要获取第二多、第三多的。而且还是每个年级内的第一、第二、第三多。对于这种问题,我们可以使用窗口函数来实现,先生成每门课程的报名人数,然后再利用row_number()生成每个年级内每门课程的排序结果,最后再通过排序结果筛选出我们需要的排序。最后运行结果如下:
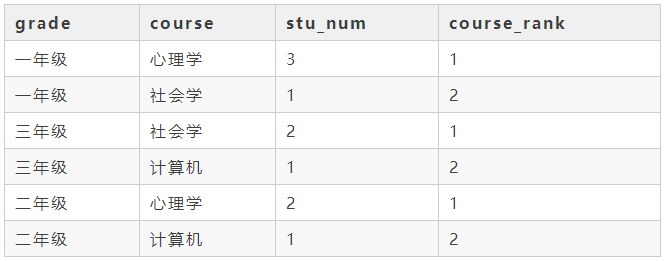
当然,我们这里可以通过where条件筛选任意排名的课程。比如如果要筛选排名第5-8的课程,只需要让where条件中的b.course_rank between 5 and 8即可。
20 求累积和
现在有一张2019年一整年的订单表consum_order_table,consum_order_table包含order_id(订单id)、uid(用户id)、amount(订单金额),现在我们想看下80%的订单金额最少是由多少用户贡献的,该怎么实现呢?
consum_order_table表如下所示:
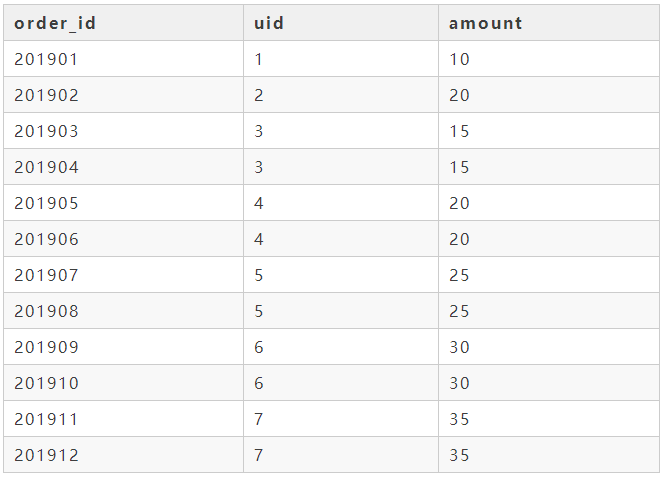
自己先想一下代码怎么写,然后再参考我的代码。
select count(uid)from (select uid ,amount ,sum(amount) over(order by amount desc) as consum_amount ,(sum(amount) over(order by amount desc)) /(select sum(amount) from demo.consum_order_table) as consum_amount_rate from (select uid ,sum(amount) amount from demo.consum_order_table group by uid ) uid_table)twhere t.consum_amount_rate < 0.8
解题思路:
我们要获取人80%的订单金额最少由多少用户贡献的,因为我们现在只有一个订单明细表,所以我们需要先生成一个人维度的订单金额表,然后再在这个人维度表的基础上去进行累积和,累计和的实现可以通过窗口函数来实现,这样就可以得到人维度的累积订单金额,在生成累积和的时候需要按照订单金额进行降序排列,这样就可以得到最少的人数,最后再利用一个子查询,获取到全部的订单金额,用累积订单金额去除全部订单金额,就可以得到累积的订单金额贡献情况。最后运行结果如下:

End.爱数据网专栏作者:张俊红作者介绍:一个数据科学路上的学习者、实践者、传播者个人公众号:俊红的数据分析之路
- 我的微信公众号
- 微信扫一扫
-

- 我的微信公众号
- 微信扫一扫
-


评论